如何实现大文件上传
本篇来讲解如何实现大文件的上传,相信大家都听说了大文件上传、分片上传、断点续传之类的术语了,这些都是大文件上传的通用技术
首先要知道为什么需要大文件上传,直接上传不行吗?由于文件的上传是由用户在前端表单发送的,前后端又是通过HTTP请求进行传输数据的。对于较小的文件可以很快的传输,而大文件就不会那么快,加上HTTP是基于TCP协议的,TCP具有时延、丢包、拥塞问题。尽管使用了HTTP2但在一个连接上无法发挥其优势。那么可以考虑通过并发文件内容可以提高传输速度和效率,对于丢失的数据包只需要重传某个数据块而已,这样就大大提高了文件传输效率和速度,以上就是大文件上传的基本原理
文件上传
对于小文件使用传统的HTTP请求一次就可以上传成功,通常就是前端使用form表单传输文件数据,这个比较简单。来看个基本的例子:
前端:基本的form表单上传
<input type="file" onChange={onFileChange} />
const onFileChange = e => {
const files = e.target.files;
if (!files?.length) return;
const file = files[0];
const formData = new FormData();
formData.append('file', file);
fetch("/api/file/upload", { method: 'post', body: formData });
}NodeJS:这里使用Nest框架,其他框架类似
export class FileController {
@Post('upload/normal')
@HttpCode(HttpStatus.OK)
@Header('Content-Type', 'application/json')
@UseInterceptors(FileInterceptor('file'))
@ApiConsumes('multipart/form-data')
async uploadNormalFile(@Body() body: IFileProp, @UploadedFile() file: Express.Multer.File) {
// 这个buffer就是文件内容
const { originalname, mimetype, buffer } = file;
return 'ok';
}
}以上就是一个简单的小文件上传和普通的json请求没有啥区别,来看下效果(图片大小3.7M)
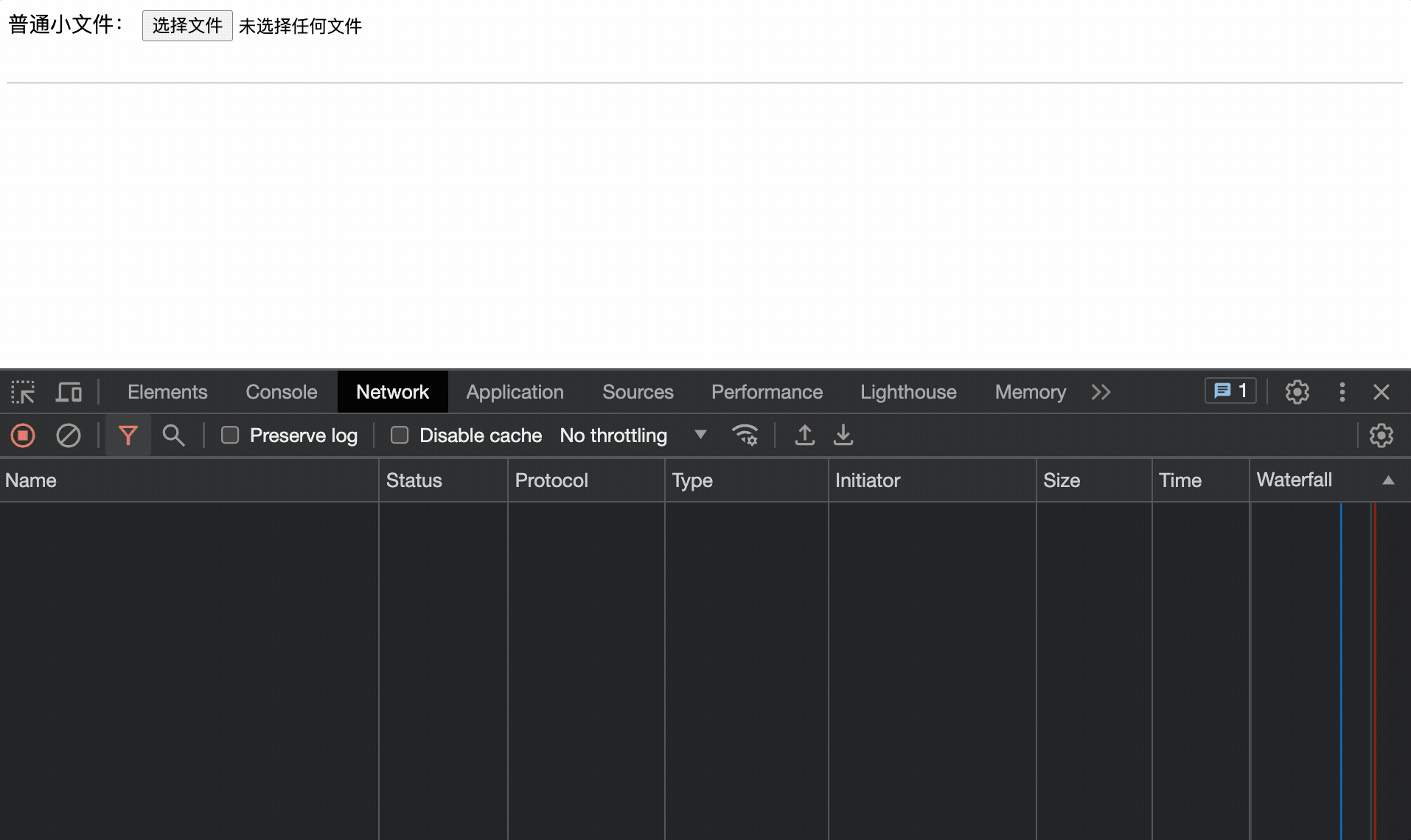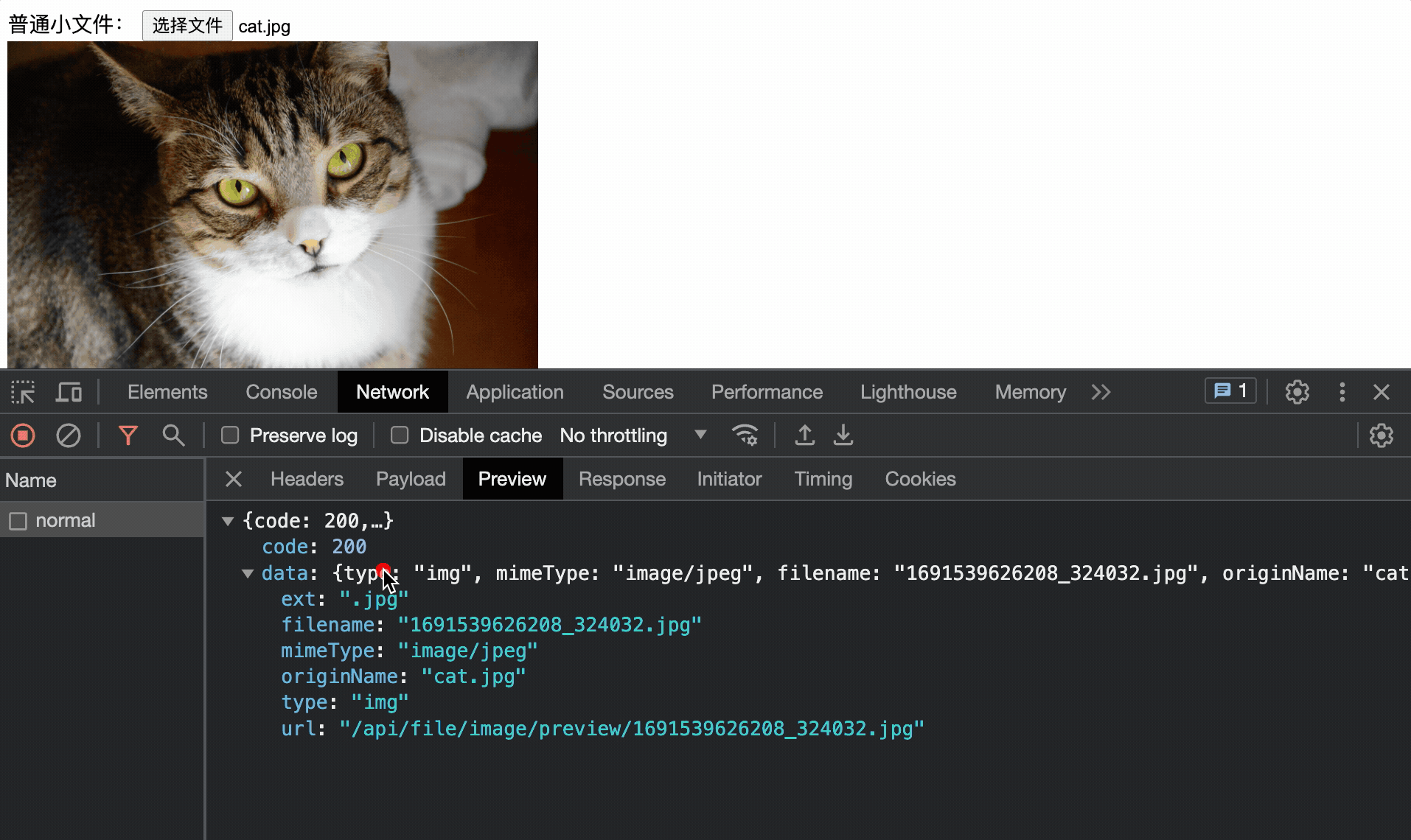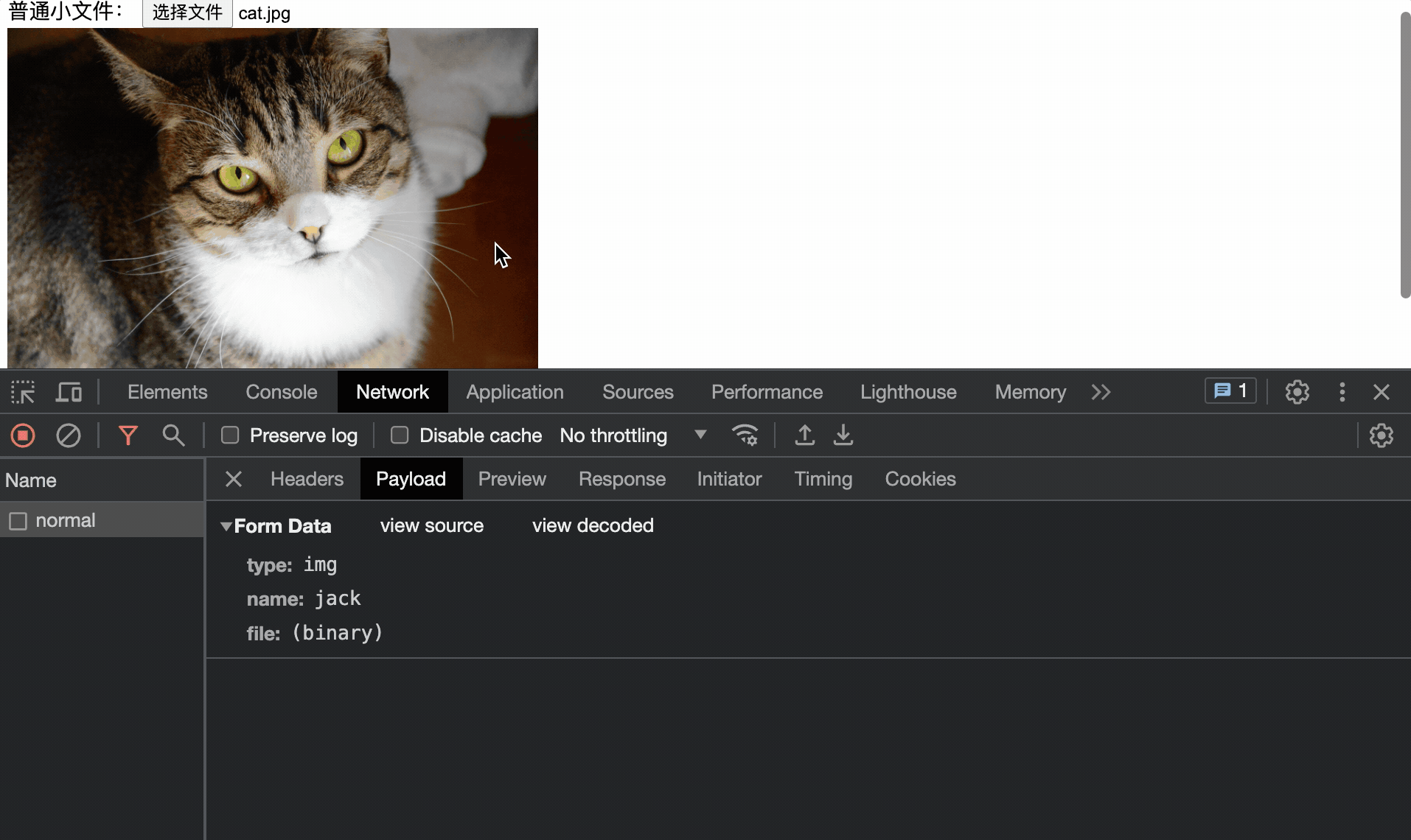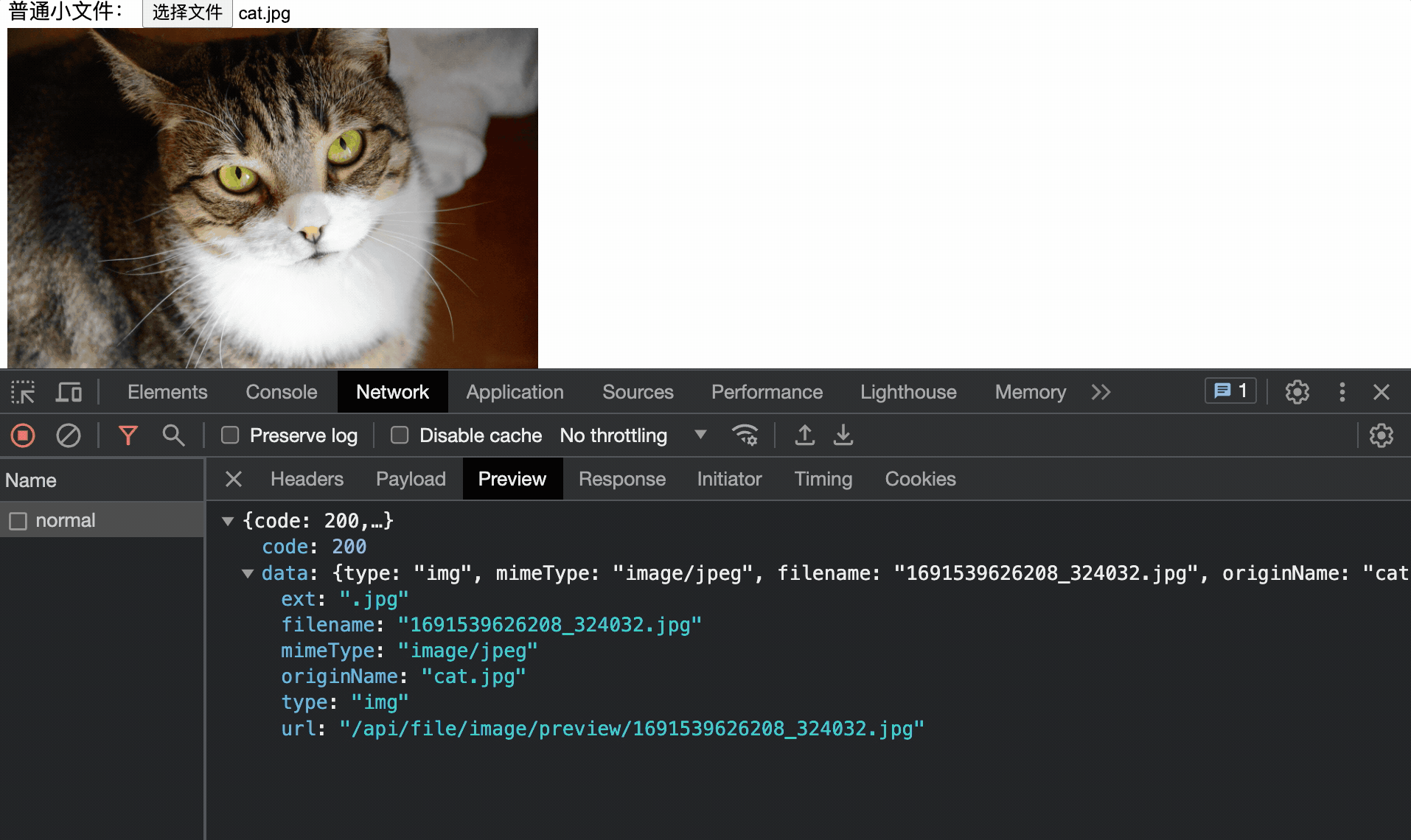
大文件问题
对于小文件将整个文件传输问题不大,如果遇到文件很大的情况就会造成HTTP请求堵塞,会出现超时、丢包、内存占用大、速度慢、不稳定等各种问题。如果一个大文件在上传了90%后突然网络中断,那么就只能重新发送整个文件,浪费宽带浪费时间,当然这种方式也会造成服务器负载压力过大、缓慢崩溃问题,可见这种一次传输对大文件是行不通的
解决方案
大文件说白了就是太大了,以至于传输负载太大、效率很低,而如果使用小文件就可以很快的传输成功。那么可以对大文件把大文件划分成很多小块,然后将小块一批一批的传输给服务器,最后服务器将这些小块再拼接成一个整体文件就可以完美解决大文件传输的痛点
文件切片传输就和小文件传输一致了,没有超时问题、也不会占用过高内存和带宽,所有切片并发传输提高传输效率。整体来说文件切片传输的优势有以下几点:
- 降低时延、基本不会超时
- 丢包几率很低效率高
- 带宽、内存占用小
- 并发传输减小传输时间
文件切片
文件切片就是对整个文件进行切割处理,然后将每个块批次传输。文件的切片涉及到的二进制方面的内容,这里你首先要了解二进制相关的内容,如:Blob、ArrayBuffer等等,如果你对这方面还不是很熟悉,可以通过我的「前端二进制」一文学习下
表单选择的文件属于File类型,File类型中包含了文件的名字、大小、修改时间等等内容,File继承于Blob类型,而Blob拥有slice方法可以对blob进行分割,这样就可以实现文件的分片了
const CHUNK_SIZE = 1024 * 1024 / 1; // 分片大小 1M
const onFileChange = e => {
const files = e.target.files;
if (!files?.length) return;
const file = files[0];
const chunks = createChunks(file); // 文件切片
}
function createChunks(file, chunksize = CHUNK_SIZE) {
const chunkList = []; // 收集所有的切片
let offset = 0; // 收集的切片总大小
while (offset < file.size) { // 当切片总大小小于文件大小时还需要继续分片
chunkList.push(file.slice(offset, offset + chunksize));
offset += chunksize;
}
return chunkList;
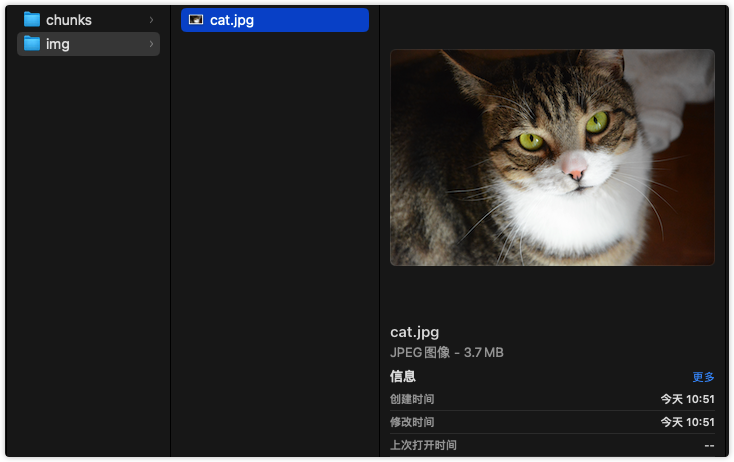
}以下是将一张3.7M大小的图片分为每块1M总共4块的切片
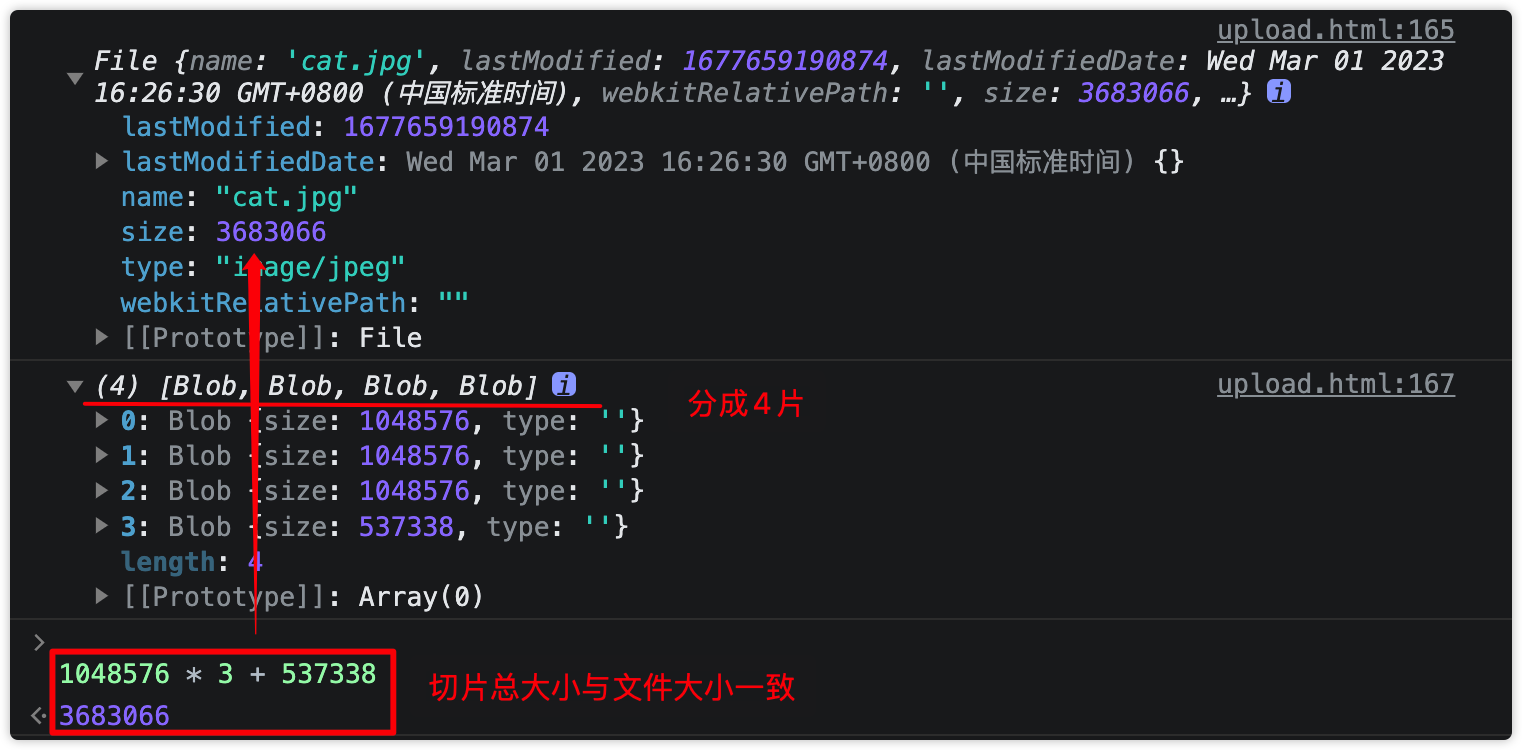
切片上传与合并
文件切片后就是传输了和普通的上传没啥区别,唯一的区别就是 将每个切片标识在整个文件中的位置 ,这样服务器在接受到切片后可以按顺序整合文件
这里简单的使用切片的下角标作为索引位置:
// 省略其它...
const chunks = createChunks(file); // 文件切片
const chunksFormData = chunks.map((chunk, index) => {
const formData = new FormData();
formData.append('file', chunk); // chunk文件数据
formData.append('filename', file.name); // 文件名字,服务器存储切片用
formData.append('index', index); // chunk索引
return formData;
});
// 切片上传
const chunksRequest = chunksFormData.map(
data => fetch("/api/file/upload/chunk", { method: 'post', data })
)
await Promise.all(chunksRequest);服务器接收到切片后,需要储存对应的切片文件,这里按文件名作为文件夹,然后将文件名-索引作为每个切片文件:
@Post('upload/chunk')
@HttpCode(HttpStatus.OK)
@Header('Content-Type', 'application/json')
@UseInterceptors(FileInterceptor('chunk'))
async uploadBiggerFile(@Body() body: IFileProp, @UploadedFile() chunk: Express.Multer.File) {
const { index, filename } = body;
const { buffer } = chunk;
// chunk目标地址
const chunkPath = path.join('chunk_cache_' + filename, filename + '-' + index);
// 创建可写流,将chunk写入
const writer = createWriteStream(chunkPath);
writer.write(chunk);
writer.end();
return body;
}以上代码只是简单的演示,部分内容不是很全
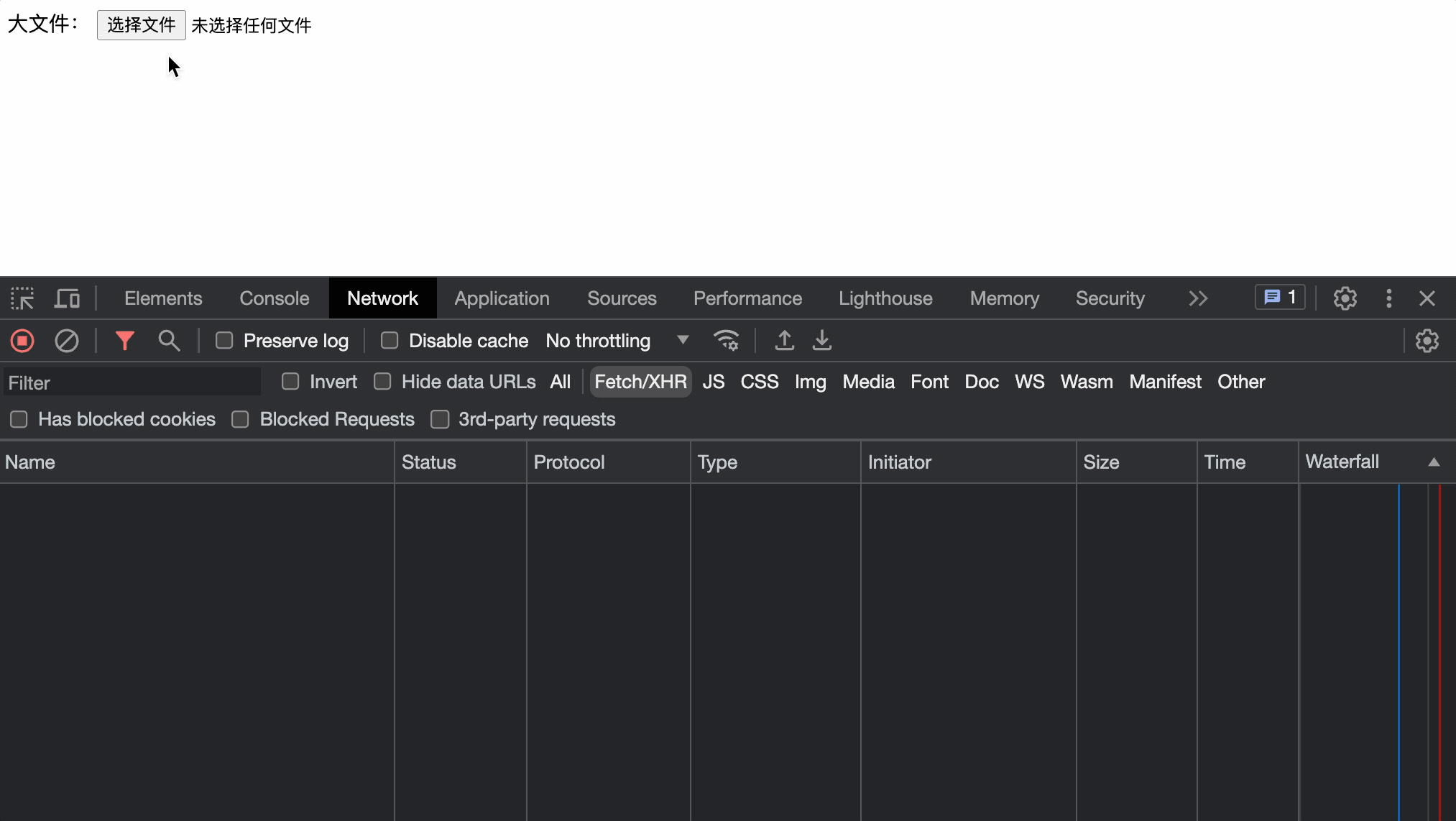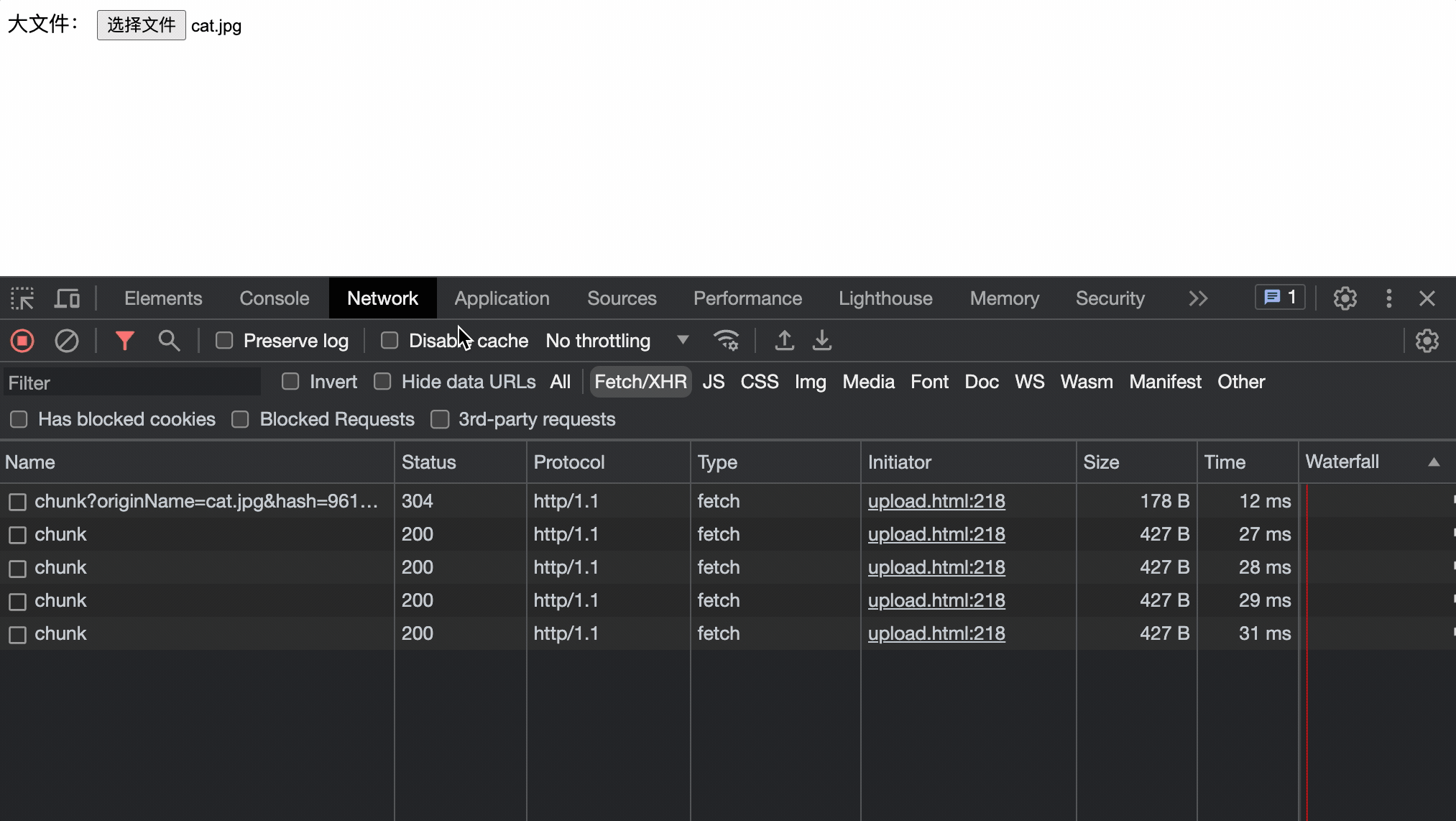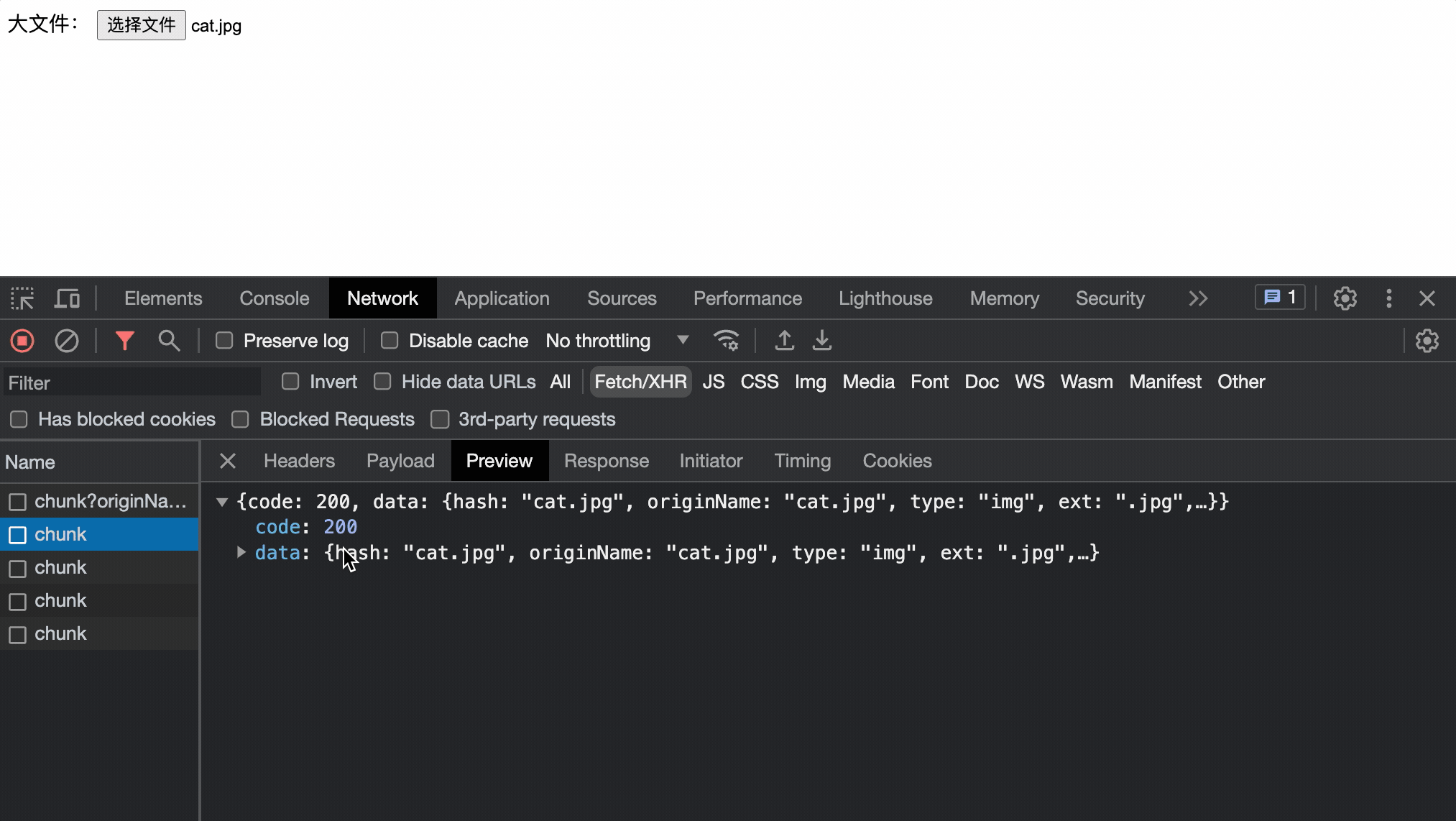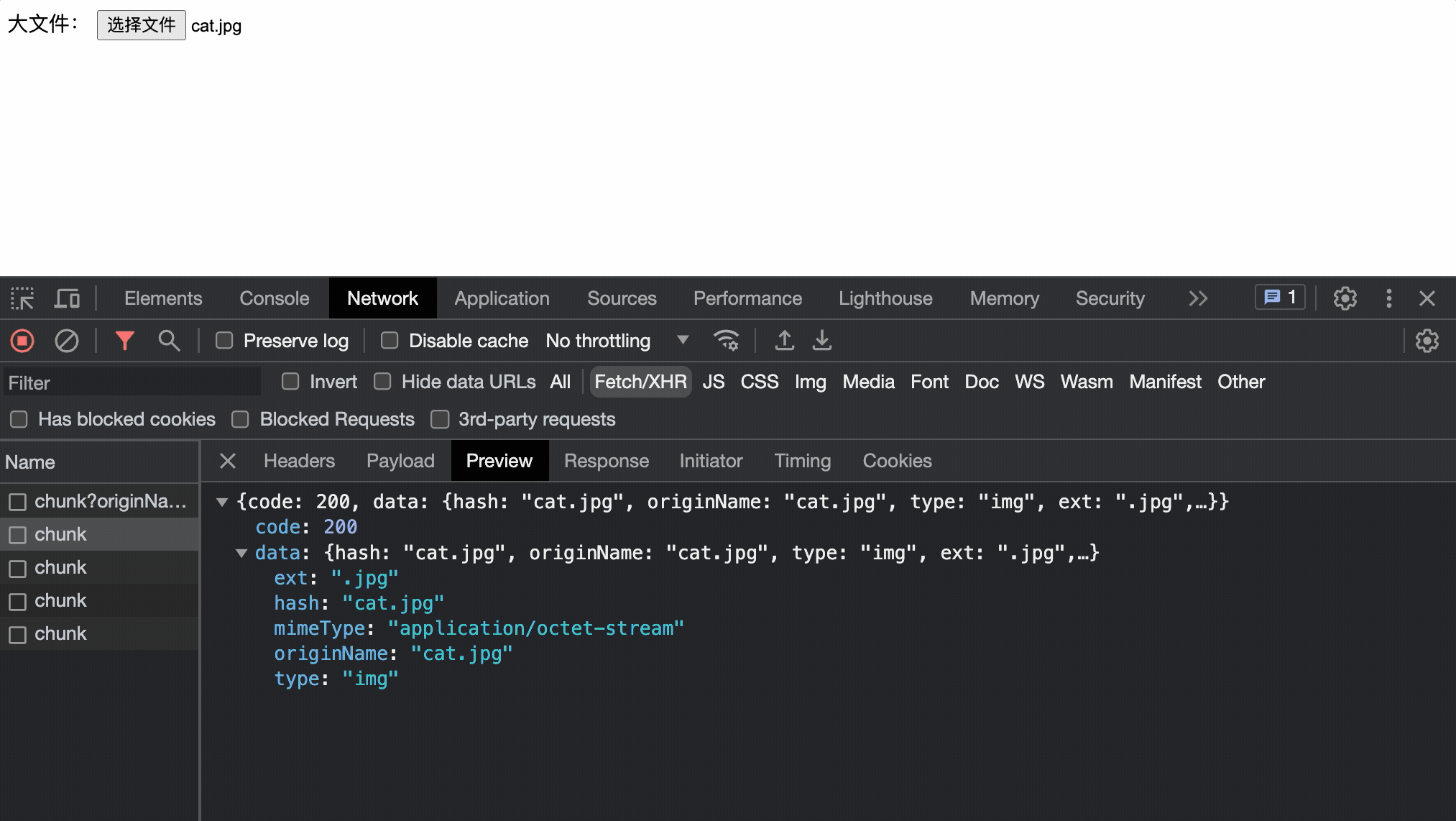
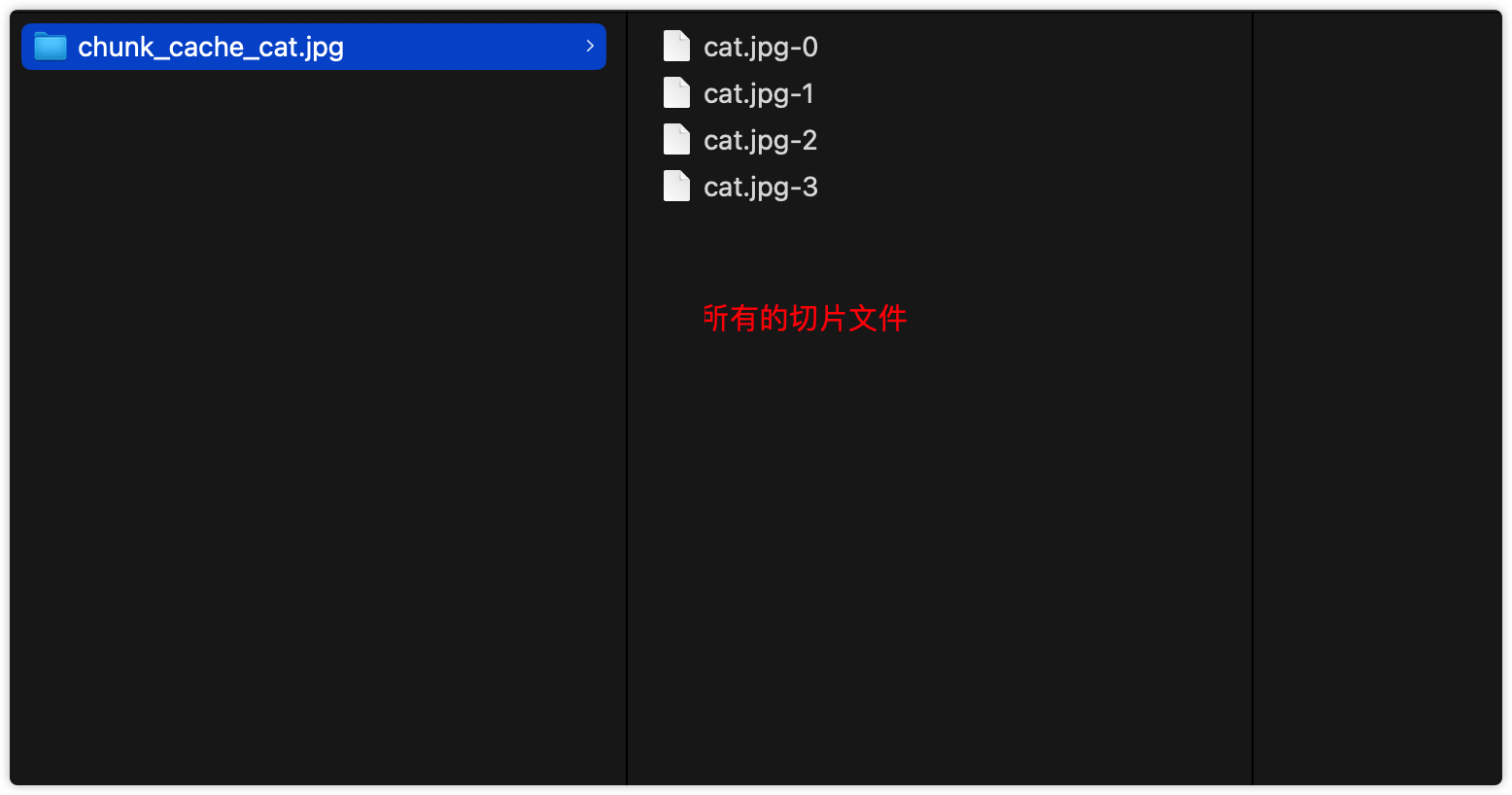
切片合并
所有的切片上传完了后就需要将文件的切片进行合并成一个完整的文件,具体的也就是将所有的chunk按顺序写入同一个文件就可以了
那么在所有的切片上传完后告诉服务器切片已经上传完了,可以合并了,通常都是发送一个合并请求
前端发送合并请求:
fetch("/api/file/upload/chunk/merge", {
method: 'post',
data: JSON.stringify({ originName: file.name }), // 告诉服务器要合并的文件
headers: { 'Content-Type': 'application/json' }
});服务器合并切片:
// 合并大文件
@Post('upload/chunk/merge')
@HttpCode(HttpStatus.OK)
@Header('Content-Type', 'application/json')
async mergeChunk(@Body() body: IFileProp) {
const { filename } = body;
const mergePath = join('img', /*originName*/ filename); // 合并位置:img/xxx.jpg
const chunkPaths = await readdirSync("chunk_cache_" + filename); // 读取所有chunk地址
await this.writeChunksToFile(chunkPaths, mergePath);
return { message: "上传成功" };
}
async writeChunksToFile(chunkPaths: string[], mergePath: string) {
// 当前chunk的写入位置
let offset = 0;
// 将所有的chunk进行从小到大排序
chunkPaths = chunkPaths.sort((a, b) => parseInt(a.match(/-(\d+)/i)[1], 10) - parseInt(b.match(/-(\d+)/i)[1], 10));
await Promise.all(
chunkPaths.map(async chunkPath => {
const reader = createReadStream(chunkPath);
// 读取当前chunk的大小
const len = await (await stat(chunkPath)).size;
// 写入文件的指定位置
const writer = createWriteStream(mergePath, { start: offset });
// 位置偏移量
offset += len;
await new Promise((resolve, reject) => {
reader.pipe(writer);
reader.on('error', reject);
writer.on('error', reject);
writer.on('finish', async () => {
writer.close();
writer.destroy();
reader.destroy();
await unlinkSync(chunkPath);
resolve(true);
});
});
}),
);
}这里只是简单的演示下合并的逻辑,实际情况应该做一次封装
当切片合并完后既可以将完整图片地址响应给客户端,客户端拿到地址就可以访问了(假如是图片)
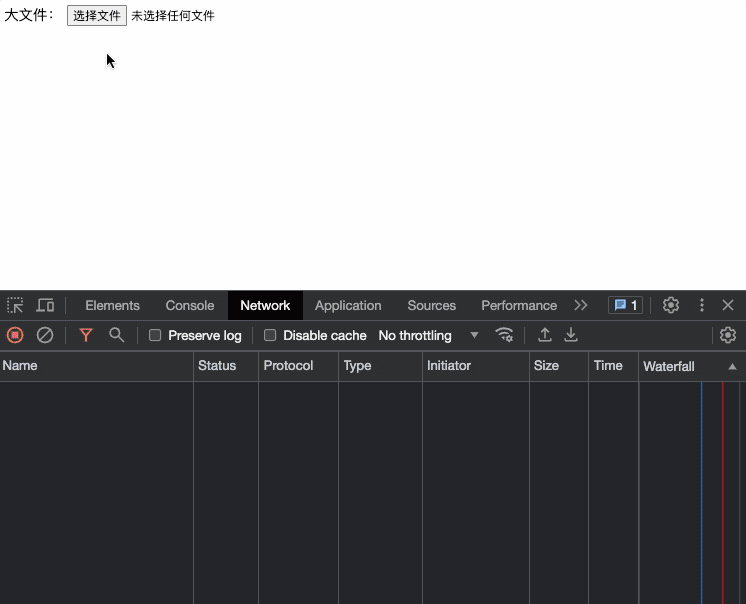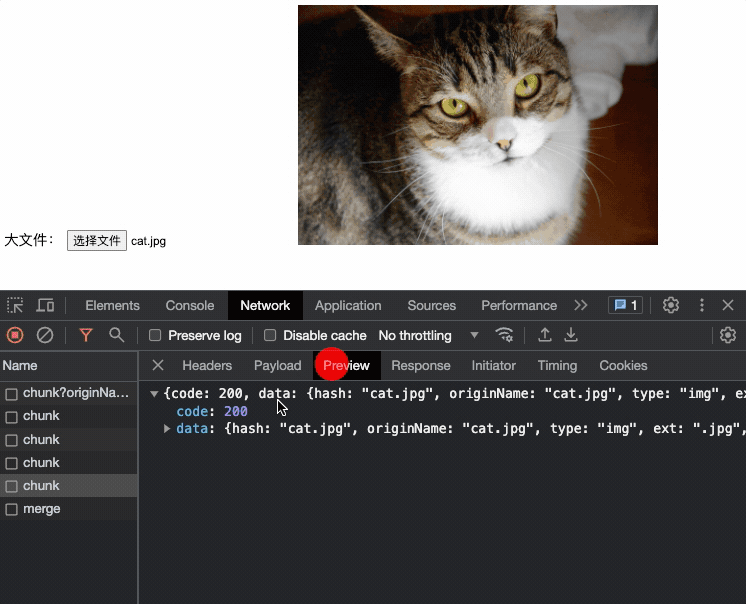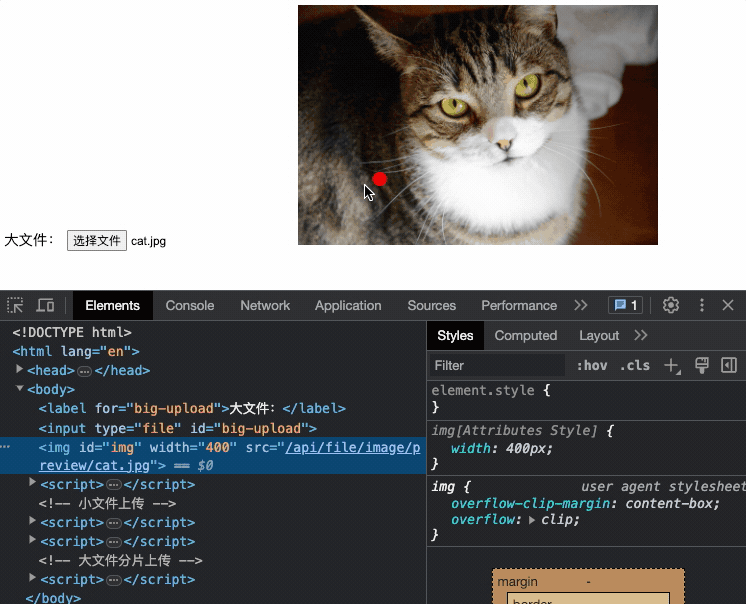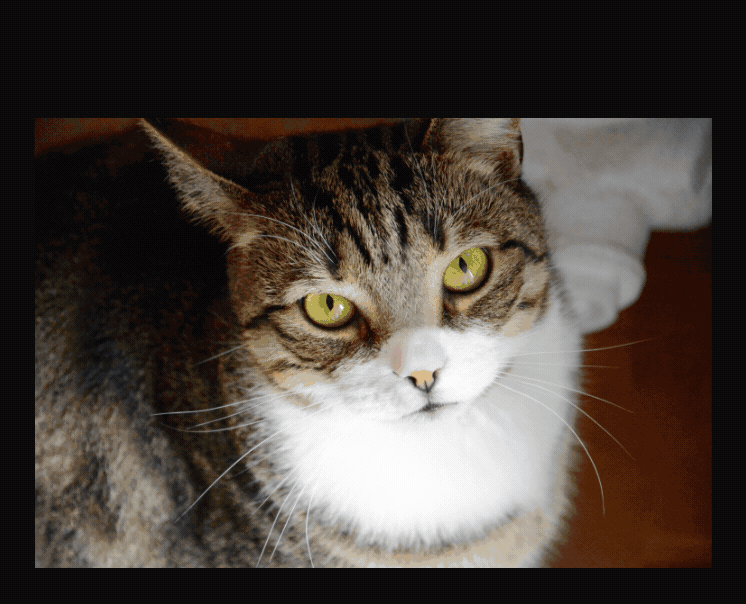
以上便是大文件上传的基本操作原理,到这里其实就已经解决了大文件上传的痛处,接下来来聊聊上传的优化
并发限制
首先就是要对切片上传进行并发限制,前面我们演示了一个比较小的图片只有3.7M大小,每个切片的大小为1M,总共也就是4个切片4个请求。对于更大的文件如镜像、视频文件就会有很多切片(假设切片的大小也为1M)
假设有1000个切片,浏览器一次性发送这么多请求会造成浏览器卡顿或崩溃,而好的做法就是限制并发数,比如保持请求数为5、10个,这样就不会造成浏览器的卡顿或崩溃了
这里简单的实现一个通用的并发请求工具函数,包含以下功能:
- 并发数限制
- 出错重试
- 出错跳过,表示成功请求,使用此属性时重试将不会起作用
/**
* 限制promise并发数
*/
interface IPromiseConcurrency {
limit?: number;
retry?: number;
skipError?: boolean;
}
interface IPromiseConcurrencyQueue {
promiseFn: (...args: any) => any;
resolve: (value: unknown) => void;
reject: (reason?: any) => void;
retry?: number;
skipError?: boolean;
}
enum CONCURRENCY_STATUS {
PENDING = "pending",
END = "end",
}
export class PromiseConcurrency {
private _limit: number;
private _retry: number;
private _activeCount = 0;
private _skipError: boolean;
private requestQueue: IPromiseConcurrencyQueue[];
private _status: CONCURRENCY_STATUS = CONCURRENCY_STATUS.PENDING;
constructor(opts?: IPromiseConcurrency) {
this._limit = opts?.limit ?? (Number?.MAX_SAFE_INTEGER || 9999);
this._retry = opts?.retry ?? 0;
this._skipError = opts?.skipError ?? false;
this.requestQueue = [];
}
get activeCount() {
return this._activeCount;
}
get pendingCount() {
return this.requestQueue.length;
}
append(
promiseFn: IPromiseConcurrencyQueue["promiseFn"],
opts?: Omit<IPromiseConcurrency, "limit">
) {
if (this._status === CONCURRENCY_STATUS.END) this.clear();
return new Promise((resolve, reject) => {
const payload: IPromiseConcurrencyQueue = {
promiseFn,
resolve,
reject,
retry: opts?.retry ?? this._retry,
skipError: opts?.skipError ?? this._skipError,
};
this.queue(payload);
});
}
private async queue(current: IPromiseConcurrencyQueue) {
const { promiseFn, resolve, reject, skipError } = current;
if (this._activeCount < this._limit) {
try {
this._activeCount += 1;
const res = await promiseFn();
resolve(res);
this._activeCount -= 1;
this.next();
} catch (err) {
if (current.retry) {
current.retry -= 1;
this._activeCount -= 1;
this.queue({
promiseFn,
resolve,
reject,
retry: current.retry,
skipError: current.skipError,
});
} else {
if (skipError) {
resolve(err);
this._activeCount -= 1;
this.next();
} else {
this._status = CONCURRENCY_STATUS.END;
reject(err);
}
}
}
} else {
this.requestQueue.push(current);
}
}
private async next() {
if (
this._activeCount < this._limit &&
this.requestQueue?.length &&
this._status === CONCURRENCY_STATUS.PENDING
) {
const nextRequest = this.requestQueue.shift()!;
this.queue(nextRequest);
} else if (this._status === CONCURRENCY_STATUS.END) {
this.clear();
}
}
clear() {
this.requestQueue = [];
this._activeCount = 0;
this._status = CONCURRENCY_STATUS.PENDING;
}
}并发演示:
function request(symbol: any, delay = 100) {
return new Promise((resolve, reject) => {
setTimeout(() => {
const flag = Math.floor(Math.random() * 10) < 5;
if (flag) {
reject(`出错了:${symbol}`);
} else {
console.log("request--------", symbol);
resolve(symbol);
}
}, delay);
});
}
const launch = async () => {
// 每次只能有1个请求,错误重试5次
const promiseC = new PromiseConcurrency({ limit: 1, retry: 5 });
try {
const res = await Promise.all([
promiseC.append(() => request(1), { retry: 10 }), // 当前请求重试10次
promiseC.append(() => request(2)),
promiseC.append(() => request(3), { retry: 0, skipError: true }), // 跳过错误
promiseC.append(() => request(4)),
promiseC.append(() => request(5)),
]);
console.log(res);
} catch (err) {
console.log(err);
}
};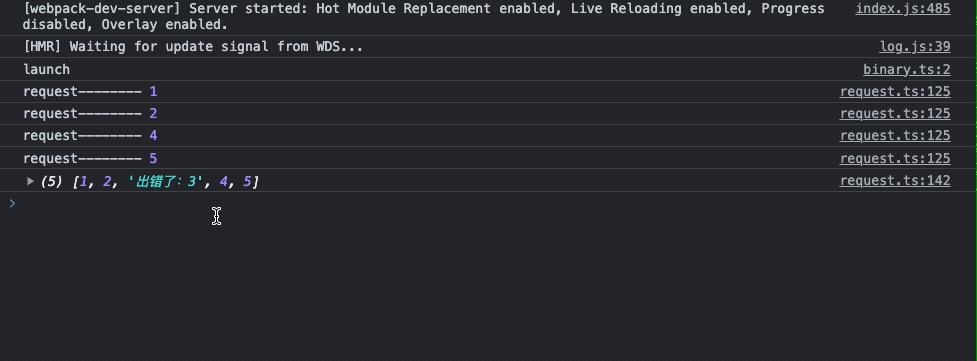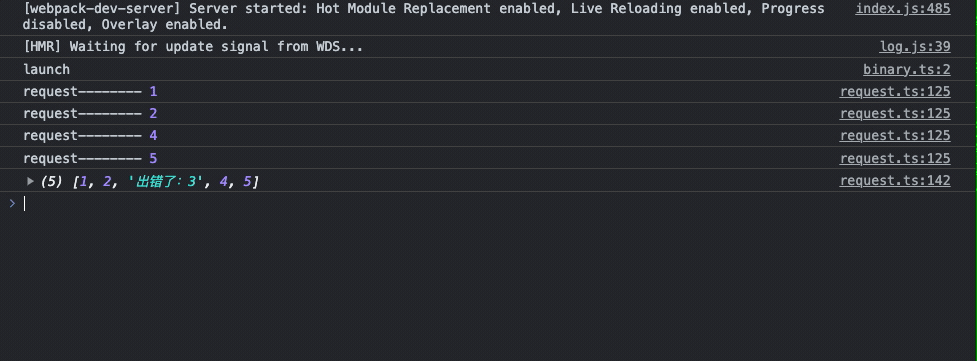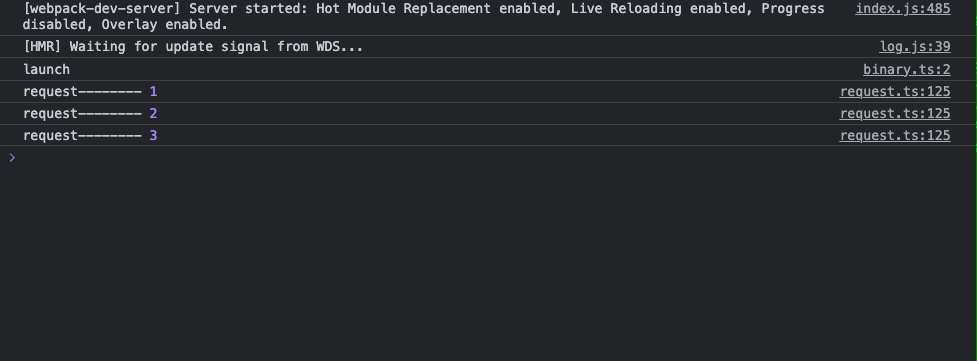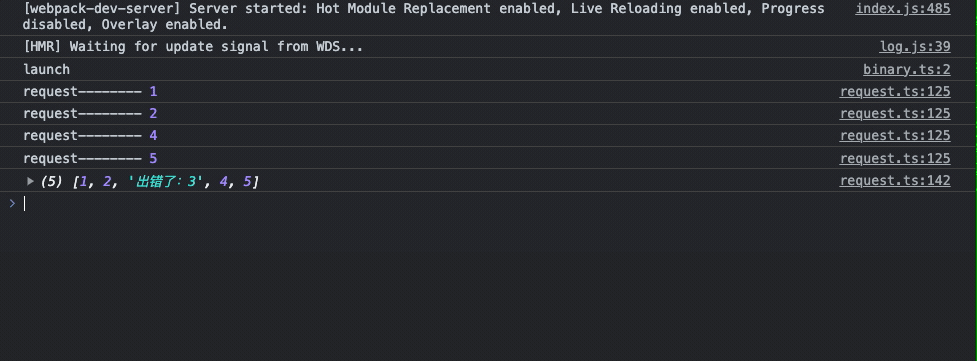
多次刷新请求有完整请求成功的,也有跳过错误和重试成功的,以上的代码自己可以跑一下试一试
用在在切片上传中使用:
// 省略其它...
const rcl = new PromiseConcurrency({ limit: 10, retry: 3 }); // 最大请求并发数为10,重试次数3
// 将所有的切片请求append到rcl控制器中
requestList = requestList.map(
(data) => rcl.append(() => request({ data, url: "/api/file/upload/chunk", method: 'post' }))
);
// 上传所有切片
const res = await Promise.all(requestList);这样即使切片再多,请求数也会限制在10个以内,这样就不会造成浏览器的卡顿了。实际情况中也应该合理安排切片大小和并发数
断点续传
尽管使用切片传输会解决前面的问题,但还是会存在网络突发故障传输中断的问题或者页面刷新后停止传输,当再次上传同一个文件时又要从头开始删除,造成不必要的重传和资源浪费,因此跳过已经上传过的文件切片可以提高传输效率
切片传输正好可以满足以上的条件,文件被分成若干个切片后是按照一定的时机或顺序传输的,已传输的切片也会被保存在服务器,所以服务器可以很好的知道已经上传了哪些切片,并将已经上传的切片列表返回给客户端,当客户端再次上传时过滤掉已经上传的切片即可
💡 实现思路: 服务器返回已经上传的切片列表,前端上传时跳过已经上传过的切片
有一个问题就是如何判断上传的文件是上次上传的文件,即文件的唯一性如何确定,只有确定了是哪个文件才可以进一步判断文件已经上传过的切片。文件的唯一性不能使用文件名简单判断,需要根据文件内容生成对应的唯一hash值,不同的文件内容不一样hash值也就不一样,这样就可以确定文件的唯一性了
这里采用 spark-md5 对文件进行hash计算,这个库可以采用增量式形式对整个文件进行hash计算性能比较出色,具体的使用方法不做介绍,自行查阅文档
const chunks = await createChunks(file);
const spark = new SparkMD5.ArrayBuffer();
const loadNext = (idx = 0) => {
const chunk = chunks[idx];
if (!chunk) {
upload(spark.end()); // 计算完hash后上传
}
const reader = new FileReader();
reader.readAsArrayBuffer(chunk);
reader.onload = e => {
spark.append(e.target.result);
loadNext(++idx);
};
};
loadNext();使用spark-md5计算完hash后,就可以上传切片了,现在需要将切片的hash传给服务器,服务器以hash值作为文件的储存地址;上传前要先请求服务器判断哪些切片已经上传过了。这里使用length和list两个属性,当length等于-1时代表已经上传过了,其余的的长度为已经上传了的切片长度,list里包含了上传过的切片
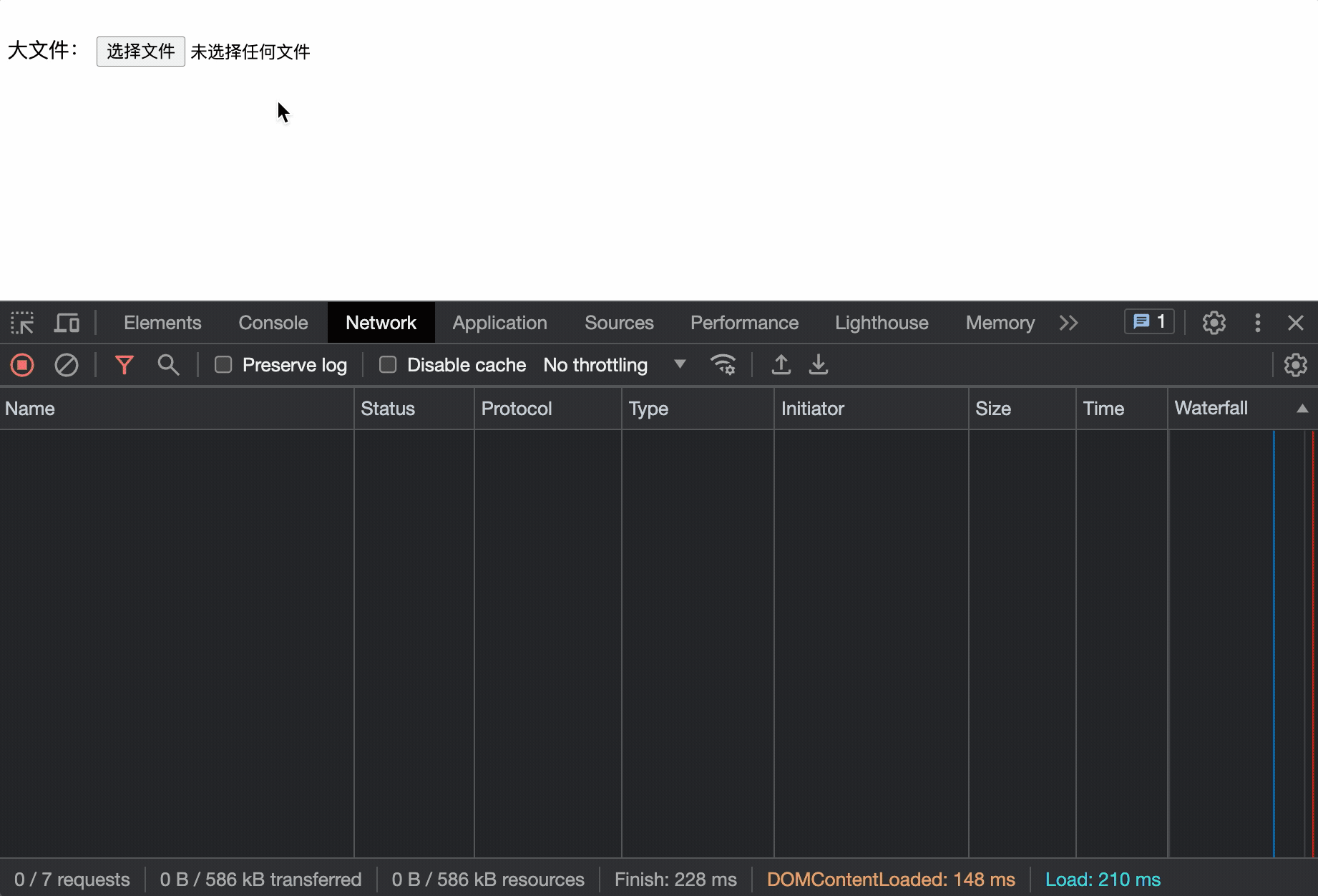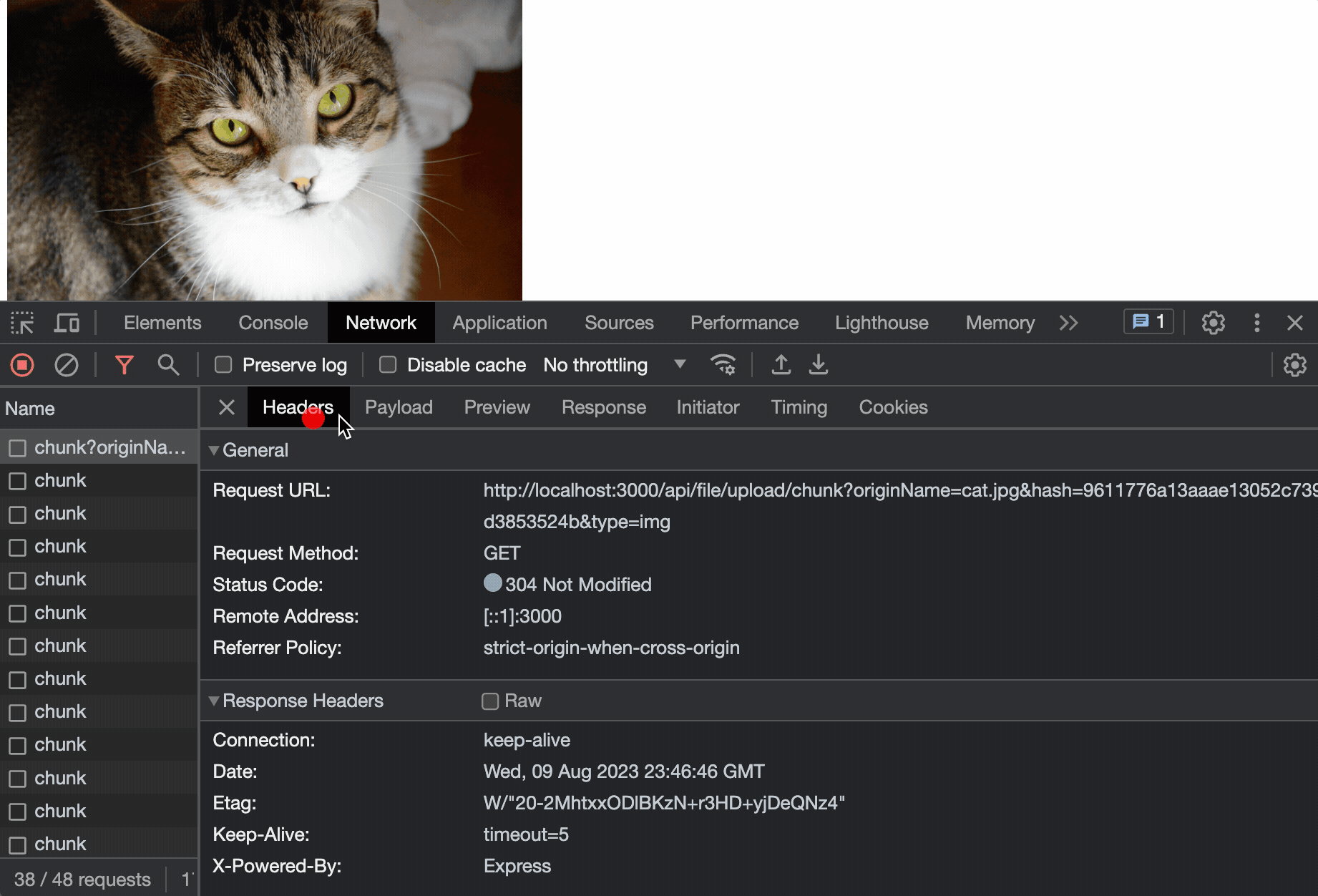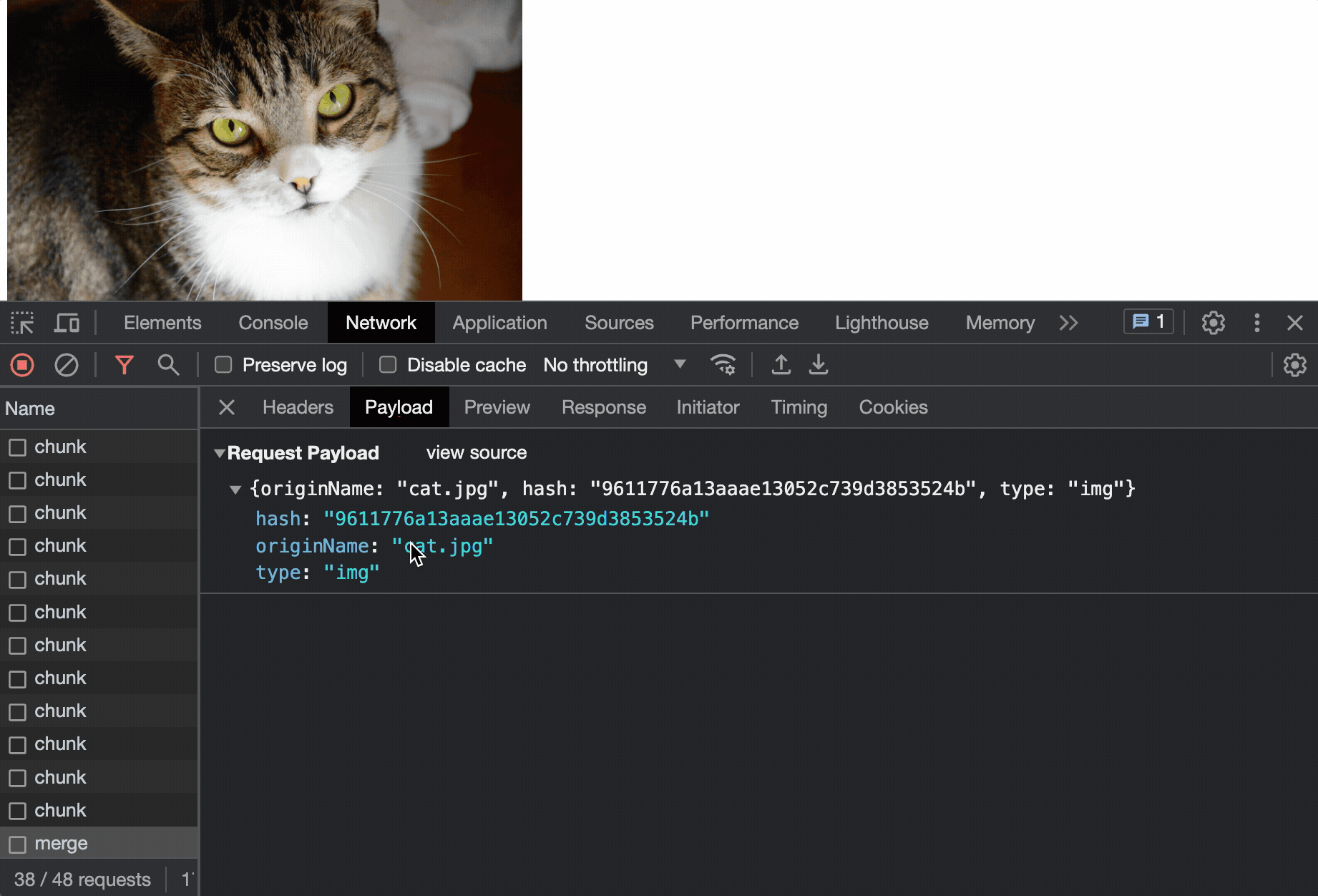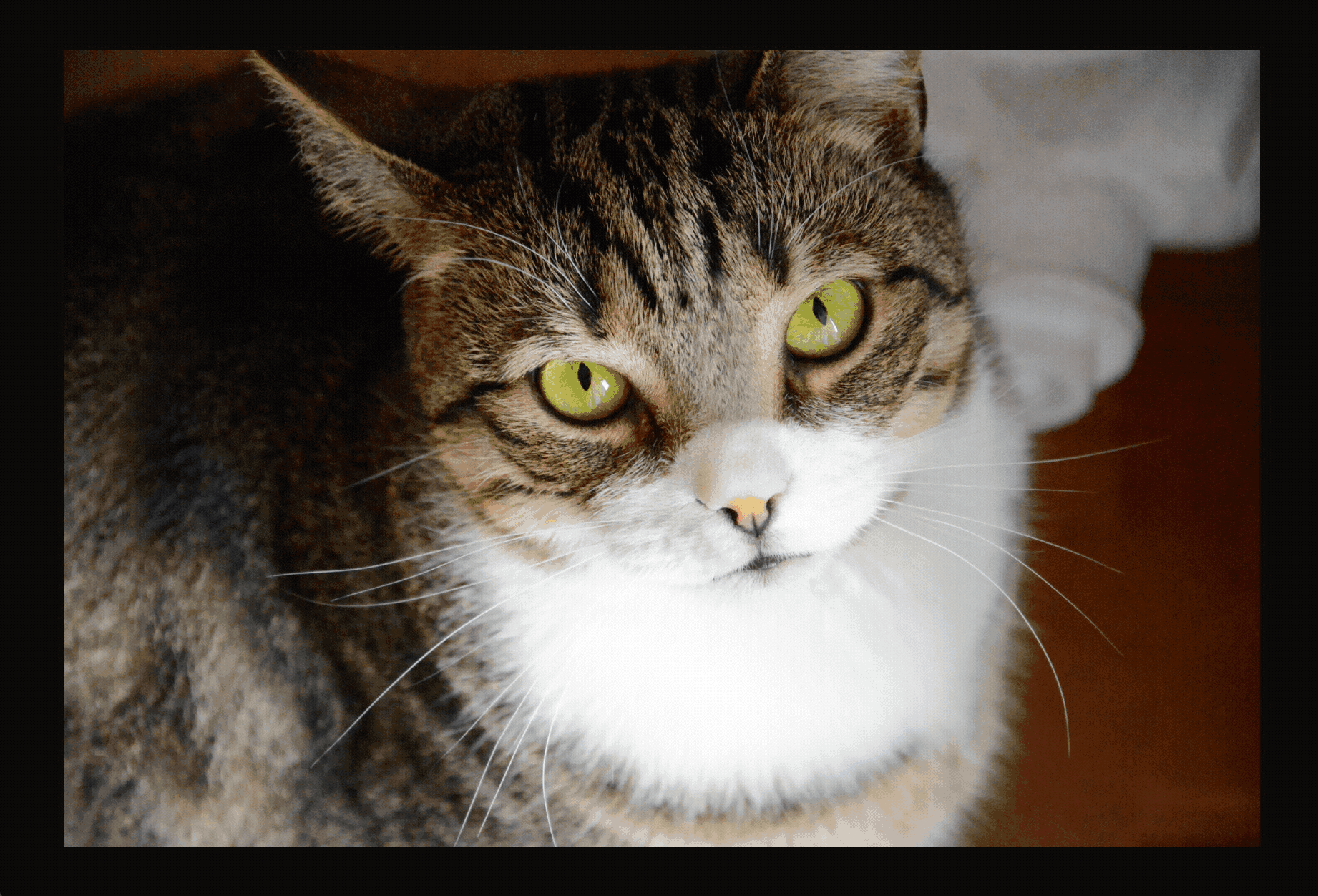
async function upload(hash: string) {
// 上传前先请求当前文件上传情况:成功上传;没上传;部分chunk上传
const uploadedList = await request({
url: `/api/file/upload/chunk?originName=${file.name}&hash=${hash}`,
headers: { 'Content-Type': 'application/json' }
});
// -1 表示已经上传成功了
if (uploadedList?.data.length === -1) {
console.log('已经上传过了');
return;
}
let requestList = chunks.map((chunk, idx) => {
const formData = new FormData();
formData.append('originName', file.name);
formData.append('chunk', chunk);
formData.append('index', idx);
formData.append('hash', hash);
return formData;
});
// 过滤掉已经上传过的切片
if (uploadedList?.data?.length > 0) {
requestList = requestList.filter(
(l, idx) => !uploadedList?.data?.list?.includes(idx)
);
}
const rcl = new PromiseConcurrency({ limit: 10, retry: 3 }); // 最大请求并发数为10
requestList = requestList.map(
(data) => rcl.append(() => request({ data, url: "/api/file/upload/chunk", method: 'post' }))
);
// 上传切片
const res = await Promise.all(requestList);
// 上传完后发送合并切片请求
const merged = await request({
url: "/api/file/upload/chunk/merge",
method: 'post',
data: JSON.stringify({ originName: file.name, hash }),
headers: { 'Content-Type': 'application/json' }
});
console.log(merged);
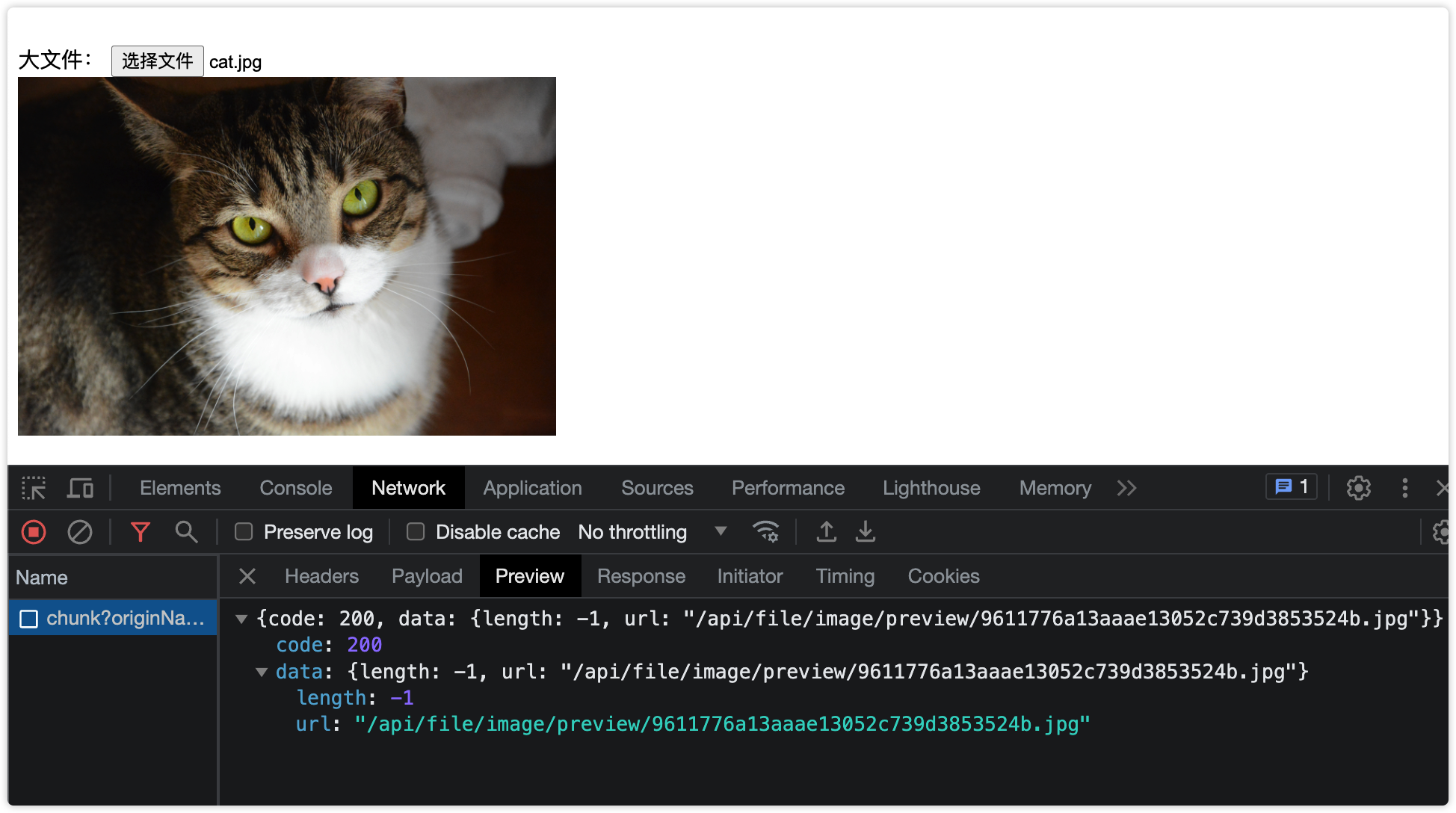
}下图为上传图片的演示效果,每个切片大小0.1M
当上传过此图片后,再次上传此图片就不会上传了,这就是文件秒传的实现
断点续传这里不再演示,你可以控制下已经上传过的切片,然后停止上传,停止后再上传同一个文件即可
切片优化
文件的hash计算会消耗大量的时间尤其对于大型文件,会划分一定的时间。由于JS是单线程的且JS引擎执行会阻塞浏览器渲染,长时间的JS计算会导致页面卡顿或者卡死现象,用户体验会变得非常差。所以对于大型计算最好交给其他线程来做,即使该线程崩溃也不会影响页面渲染
浏览器提供了 WebWoker 可以使用其他线程,我们来优化下文件hash计算
worker线程:
// /js/web-worker/upload.worker.js
self.importScripts('/js/spark-md5.min.js');
self.onmessage = e => {
const { chunks } = e.data;
const spark = new SparkMD5.ArrayBuffer();
const loadNext = (idx = 0) => {
const chunk = chunks[idx];
if (!chunk) {
self.postMessage({
hash: spark.end(),
});
return self.close();
}
const reader = new FileReader();
reader.readAsArrayBuffer(chunk);
reader.onload = e => {
spark.append(e.target.result);
loadNext(++idx);
};
};
loadNext();
};主线程:
const chunks = await createChunks(file);
const worker = new Worker('/js/web-worker/upload.worker.js');
worker.postMessage({ chunks });
worker.onmessage = async e => {
const hash = e.data.hash; // 拿到计算的hash值
// 省略...
}这样使用其他线程后即使再大的文件也不会影响主线程了,大大提升用户体验
文件秒传
参考断点续传
功能完善
到这里基本上将大文件上传的核心功能都已讲完,基本上已经可以满足上传需求了。文中大多都是在说原理实现,没有讲过多的细节,实际情况应添加相关的交互,如:进度条等等。进度包含总进度、切片进度、hash计算进度等等,都比较简单这里就不再赘述了
再者就是动态控制切片大小,为什么要这么做呢?由于我们是基于HTTP发送的,HTTP基于TCP,TCP具有慢启动的特征,刚开始就传输一个大胖子肯定吃不消,所以动态改变每个chunk大小可能传输效果更好。但这个需要你额外的计算每次传输时间来动态改变等等,有兴趣的可以试试
其他的优化可以自行脑补
总结
大文件上传不能像传统的数据传输一样直接发送,由于文件太大需要将其分割成若干个小块分批次传输,可以大大提高传输效率,还能实现秒传、断点续传功能。大文件上传就好比高速公路上运输一个超大超大东西,一辆车肯定很难完成任务很有可能翻车,如果将这个搭建分成好多小件交给n辆车,就可以很快解决这个问题了。主线程上不能执行高密集型的计算任务,不然会卡顿页面造成假死现象,巧用WebWoker小帮手实现多线程计算
感谢支持



