NodeJS搭建web服务器
上一篇文章我们对NodeJS有了一个全面的了解和认识,那这篇文章就来带大家搭建一款可以真正使用的web服务器(HTTP服务器)。本篇文章将实际项目中频率很高的一些使用场景和问题都一一罗列下来,带读者快速熟悉真实的开发环境中问题和解决方案
文中大部分都以NodeJS框架作为示例,也会有少许的原生部分,但基本都是可以互用的,读者可以自行参考改善
小贴士
文章中涉及到的代码示例你都可以从 这里查看 ,若对你有用还望点赞支持
创建服务
搭建web服务器非常简单,只需要几行代码,我们通过使用原生代码和框架代码分别演示下
先使用node原生模块创建服务:
const { createServer } = require("node:http");
const server = createServer((req, res) => {
res.writeHead(200, { "Content-Type": "text/plain" });
res.end("Hello World\n");
});
server.listen(3000, () => console.log("server start on 3000 port."));使用express框架搭建服务:
// 使用前请先安装
const express = require("express");
const app = express();
app.get("/", (req, res) => {
res.send("Hello World");
});
app.listen(3000, () => console.log("server start on 3000 port."));上面我们分别使用原生和框架搭建了web服务器,可以看出他们区别不大,都是几行代码就可以完成;值得注意的是express的可以定义具体的请求方式,使用起来更简单些
现在我们请求搭建好的地址:

相较于其他语言的web服务器,NodeJS的使用更加轻松简单,接下来我们一步一步添砖加瓦来完善服务器吧
路由管理
小贴士
本次路由的处理示例在原生NodeJS和框架(如express、koa)中都可以使用
实际工作中的项目通常都涉及到很多很多的业务,那必然就会有很多的接口提供给前后端进行数据沟通,面对庞大的业务往往都会进行模块化处理
模块化开发是一种将应用程序拆分为多个独立、可重用模块的设计方法,这种方法能够显著提升开发效率和代码质量。通过模块化,开发者可以专注于小范围功能的实现,降低代码耦合性,从而实现更高的可维护性和扩展性
那么路由也是可以模块化处理,路由本质就是不同模块的的业务端点,来看看路由的模块划分
划分模块
假设我们有user、shopping两个业务模块,那么我们就可以创建2个单独的模块文件:
server.js
router.js # 应用路由入口
module # 业务模块
├── shopping
│ ├── index.js
│ └── controller.js # shopping业务路由
└── user
├── index.js
└── controller.js创建模块Controller
先来创建shopping模块的controller业务:
import { BaseController } from "../../helper/base-controller.js";
export class ShoppingController extends BaseController {
// shopping定义的所有路由
routes = {
"get:/shopping/?$": this.getShoppingList,
"post:/shopping/\\d+$": this.deleteShopping,
};
/** 请求购物车列表 */
getShoppingList(req, res) {
// todo ...
res.end("shopping list");
}
/**删除购物车 */
deleteShopping(req, res) {
res.end("delete shopping");
}
}再来创建user模块的controller业务:
import { BaseController } from "../../helper/base-controller.js";
export class UserController extends BaseController {
routes = {
"get:/user/list": this.getUserList,
};
/** 请求用户列表 */
getUserList(req, res) {
res.end("user list");
}
}实现Controller基类
这里所有的controller都继承了BaseController,来看下它的实现:
export class BaseController {
static _instance;
static get instance() {
if (!this._instance) {
this._instance = new this();
}
return this._instance;
}
// 用来处理路由业务
handle(req, res) {
const routes = this.routes;
const method = req.method.toLowerCase();
const noParamsUrl = req.url.split("?")[0];
const matchedURL = `${method}:${noParamsUrl}`;
const hitRoute = Object.keys(routes).find((route) => {
const regexp = new RegExp(route)
return regexp.test(matchedURL);
});
if (hitRoute) {
routes[hitRoute](req, res);
} else {
res.writeHead(404, { "Content-Type": "text/plain" });
res.end("Not Found");
}
}
}BaseController主要来实现路由分发到当前模块后,进行当前模块路由的最终匹配,当匹配到了就会执行对应的路由回调业务,否则返回404
创建应用路由
接下来来看看路由总入口router.js的内部实现,本质就是一个函数中间件,根据路由遍历路由列表进行匹配:
// 定义app的路由
import { ShoppingController } from "../module/shopping/index.js";
import { UserController } from "../module/user/index.js";
// 通过正则将对应业务路由的唯一前缀与controller匹配
const APP_ROUTES = {
"^/shopping/?": ShoppingController,
"^/user/?": UserController,
};
export function useRouter(req, res) {
console.log(`${req.method.toUpperCase()} ${req.url}`);
const url = req.url;
let hit = false;
for (const route in APP_ROUTES) {
if (new RegExp(route).test(url)) {
hit = true;
APP_ROUTES[route].instance.handle(req, res);
return;
}
}
if (!hit) {
res.writeHead(404, { "Content-Type": "text/plain" });
res.end("Not Found");
}
}使用路由
router主要就是在接受到请求后根据请求的路由与app的路由表进行匹配,匹配到对应的模块后然后交由对应模块进行处理,如果没有匹配到对应的模块就返回404
最后就是将应用路由中间件放入HTTP服务器中使用即可:
import { createServer } from "node:http";
import { useRouter } from "./router/index.js";
const server = createServer(useRouter);
server.listen(3000, () => console.log("server start on 3000 port."));来看下真实的请求效果:
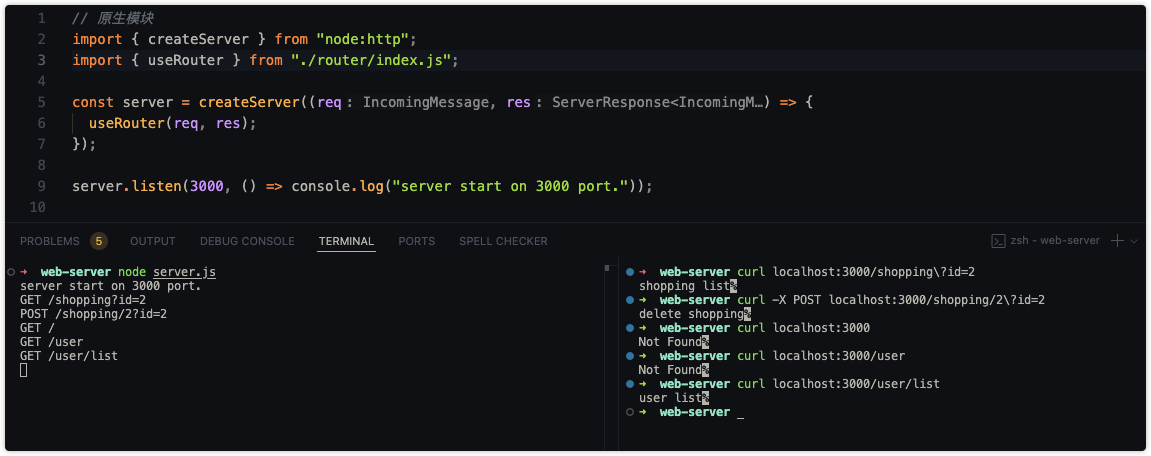
上面就是基于模块分发路由的基本实现,从这种架构划分来看即使新增更多的模块也会感觉非常的清晰,实现模块业务的解耦。当然这只是提供一个简单的解决思路,要实现更加健壮的功能需要不断的去发现实现,如:路由模块的匹配可以借助 PathToRegexp 实现更复杂的匹配规则
中间件管理
中间件管理 是现代应用开发中管理请求处理逻辑的核心方式之一,通过分层设计的理念,将应用的功能拆分成独立的中间件模块,分别负责特定的任务,如身份验证、日志记录、错误处理、请求解析等。中间件的核心思想是“流水线式”处理,即请求在进入应用后会按顺序通过一系列中间件,每个中间件可以执行某些操作,并决定是否将请求传递给下一个中间件
如何进行中间件管理:
明确中间件职责:确保每个中间件只负责单一职责,例如处理静态资源、校验请求、设置响应头等,从而保持逻辑清晰按顺序加载中间件:中间件的执行顺序非常重要,应根据功能依赖关系合理安排加载顺序。例如,身份验证中间件应在业务逻辑之前加载使用框架内置的中间件管理:在 Express 或 Koa 等框架中,通过 app.use() 或 app.middleware() 方法注册中间件,便于统一管理和维护模块化中间件:将中间件抽离为独立模块,存放在特定目录(如 middlewares/),以便在多个路由或功能中复用统一错误处理:在所有中间件的最后加载一个错误处理中间件,用于捕获前面中间件的异常并生成统一的响应
处理跨域
跨域的问题在实际开发中可能经常会碰到,一般都会由后端或者运维开发者协助处理的。跨域是怎么产生的往期文章已经说过了,如果你还不清楚,可以去阅读 HTTP协议及安全防范 一文
这里NodeJS也就充当为后端,只有前端和后端在浏览器以HTTP请求为媒介时就可能产生跨域,解决办法也很简单:
export function Cors(req, res, next) {
if (req.method === "OPTIONS") {
res.writeHead(204, {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET,POST,PUT,DELETE,OPTIONS",
"Access-Control-Allow-Headers": "Content-Type,Authorization",
});
res.end();
} else {
next();
}
}然后将应用中所需要的中间件按顺序串联在一起:
const server = createServer((req, res) => MiddlewareQueue(req, res, [Cors, useRouter]));这里我们新增了MiddlewareQueue辅助函数用来执行所有的中间件,来看下它的实现:
export function MiddlewareQueue(req, res, queue = []) {
function next() {
const middleware = queue.shift();
if (middleware) {
middleware(req, res, next);
}
}
next();
}静态资源
服务端通常会放一些静态资源,如:public目录下会放ico、图片、静态页面等等,这些资源都不需要参与打包,使用url可以直接访问,这类静态资源可以直接通过网关指到对应的文件路径即可;这里我们来看下在NodeJS服务中如何访问这些资源
使用原生NodeJS来访问这些资源会相对麻烦些,主要逻辑就是读取对应目录下的所有文件系统信息,如果是目录时还会嵌套读取,最后在客户端请求时和请求路径进行匹配
而这里使用框架会简单很多:
// app.use(express.static("public"));
app.use((req, res) =>
MiddlewareQueue(
req,
res,
[express.static("public"), Cors, useRouter]
)
);GZip压缩
生产环境为加速页面的传输速度,通常都会使用一些压缩手段,比如:GZIP、BR等等方式,然后在网关或者服务器上直接返回压缩后的文件,浏览器根据返回的压缩协议进行解压
小贴士
使用GZip压缩需要在打包时产生对应的.gz文件,读者可以使用熟悉的打包工具补充这部分;最好不要在请求时再对响应内容进行gzip压缩,这在高并发期间会严重降低响应速度
在node中我们使用 compression 来间接匹配对应资源的压缩文件,使用也很简单:
app.use(
compression({
filter: (req: Request, res: Response) => {
if (/\.(woff2|gz|robots\.txt?)/i.test(req.path)) return false;
return compression.filter(req, res);
},
})
);身份认证
身份认证 是构建安全后端应用程序的重要环节,通过验证用户的身份来确保访问资源的合法性。常见的认证方式包括 基于Session、JSON Web Token (JWT)等,每种方式都适用于不同的场景
借助 NodeJS 的灵活性,可以结合很多中间件快速实现身份验证。无论是登录态的管理,还是权限的校验,NodeJS 提供了强大的工具链,帮助开发者在保证用户体验的同时,确保系统安全
cookie
安装 cookie-parser 第三方工具包,可以在request对象上获取到JSON序列化好的键值对,非常方便:
import cookieParser from "cookie-parser";
app.use((req, res) =>
MiddlewareQueue(
req,
res,
[express.static("public"), Cors, cookieParser(), useRouter]
)
);
// 路由中使用
getUserDetail(req, res) {
console.log("获取cookie:", req.cookies);
res.end("user detail");
}session
使用 express-session 第三方工具包来解决session问题:
import expressSession from "express-session";
app.use((req, res) =>
MiddlewareQueue(req, res, [
// 省略...
expressSession({
secret: "mySecretKey",
resave: false,
saveUninitialized: true,
cookie: {
maxAge: 3600000,
httpOnly: true,
},
}),
])
);token
在 Express 中使用 Token 进行身份认证是一种常见且安全的方式,尤其是在需要无状态(stateless)认证的场景下。通过 Token,服务器可以避免使用会话存储,提升扩展性
这里使用 jsonwebtoken 来生成token:
import jwt from "jsonwebtoken";
// 定义密钥(用于签名和验证 Token)
const SECRET_KEY = "mySecretKey";
// 路由中使用
/** 生成token */
createToken(req, res) {
const user = {
id: 1,
username: "admin",
};
// 创建 JWT
const token = jwt.sign(
{ id: user.id, username: user.username },
SECRET_KEY,
{ expiresIn: "1h" }
);
res.json({ token });
}生成了token后在后续的请求中需要携带,然后在需要鉴权的业务中验证token:
/** 验证token */
validateToken(req, res) {
const authHeader = req.headers.authorization;
const token = authHeader.split(" ")[1]; // 提取 Token
// 验证 Token
jwt.verify(token, SECRET_KEY, (err, user) => {
if (err) {
return res.status(403).json({ message: "Token is invalid or expired" });
}
// Token 验证成功,返回用户数据
res.json({ message: "Access granted", user });
});
}来看下最后的效果:
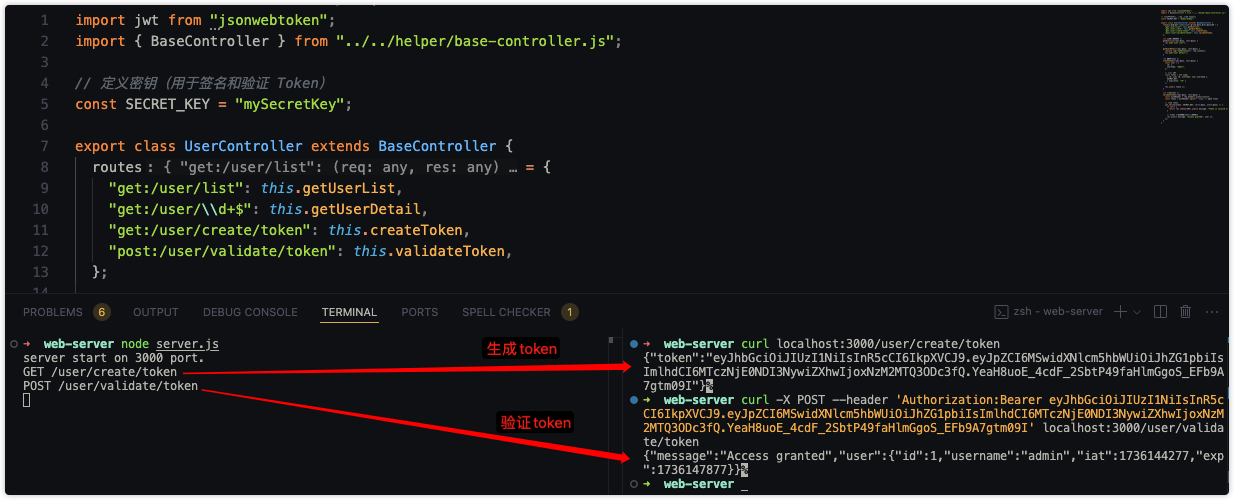
使用Token的优势与注意事项:
优势:
- 无需存储会话数据,减轻服务器压力
- 支持跨域和分布式系统
- Token 是自包含的,包含用户的所有必要信息
注意事项:
- 使用 HTTPS 传输 Token,不要将敏感信息存储在 Token 中
- 使用短时效 Token 和刷新机制(Refresh Token)
模板引擎
在 Node.js 中,模板引擎用于生成动态 HTML 内容。常见的模板引擎有 EJS、Pug(原名 Jade)、Handlebars 等。以下是使用 ejs 模板引擎的简单示例
安装模板引擎:
npm install ejs设置模板引擎:
// 设置模板引擎为 ejs
app.set('view engine', 'ejs');
// 设置模板文件存放的目录
app.set('views', './views');创建一个模板引擎页面:
<!DOCTYPE html>
<html>
<head>
<title><%= title %></title>
</head>
<body>
<h1><%= message %></h1>
</body>
</html>客户端请求时返回对应的页面:
import { BaseController } from "../../helper/base-controller.js";
export class PageController extends BaseController {
routes = {
"get:/page/home/?$": this.renderHomePage,
};
/** 渲染home页面 */
renderHomePage(req, res) {
// home为模板的文件名
res.render("home", { title: "EJS模板引擎", message: "Hello, EJS!" });
}
}请求效果:
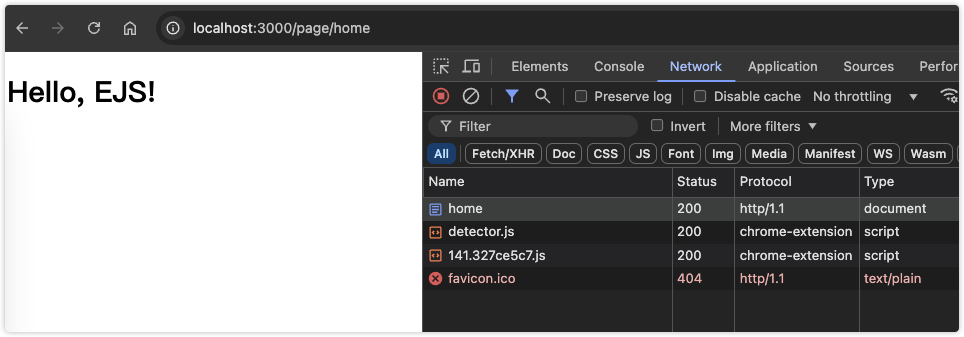
连接数据库
NodeJS 使用数据库是后端开发的重要环节,通过结合数据库驱动或 ORM 框架,可以高效地实现数据存储与管理。例如,使用 mysql2 驱动操作 MySQL,或通过 ORM 工具如 Sequelize 处理复杂关系型数据,开发者可以便捷地完成 CRUD(增删改查)操作,同时实现参数化查询以防止 SQL 注入
此外,NodeJS 的异步特性和连接池机制能够优化数据库性能,应对高并发场景,为构建高效、可扩展的全栈应用提供坚实基础;这里就简单介绍下MySQL与mongodb的使用
NodeJS使用MySQL
小贴士
本地机器使用MySQL必须要有相应的环境,推荐使用docker运行MySQL简单快捷
在 Express 中使用 MySQL 数据库,可以通过 mysql 或 mysql2 等库与 MySQL 进行交互
使用npm安装mysql2依赖包:
npm install mysql2初始化连接到对应的数据库:
import mysql from 'mysql2/promise';
const connection = await mysql.createConnection({
host: 'localhost',
user: 'root',
database: 'test',
});简单的查询语句:
const [results, fields] = await connection.query(
'SELECT * FROM `table` WHERE `name` = "Page" AND `age` > 45'
);为了避免SQL注入等安全问题,可以使用占位符进行变量的赋值:
const [results, fields] = await connection.execute(
'SELECT * FROM `table` WHERE `name` = ? AND `age` > ?',
['Rick C-137', 53]
);连接池通过重用以前的连接来帮助减少连接到MySQL服务器所花费的时间,使它们保持打开状态,而不是在使用它们时关闭
// 创建连接池
const pool = mysql.createPool({
host: 'localhost',
user: 'root',
database: 'test',
waitForConnections: true,
connectionLimit: 10,
maxIdle: 10,
idleTimeout: 60000,
queueLimit: 0,
enableKeepAlive: true,
keepAliveInitialDelay: 0,
});以上只是简答的使用示例,更多使用技巧可以参考官方文档。当然还有更多高级使用工具如ORM等等,这些推荐在NestJS中使用
NodeJS使用MongoDB
在 Express 中使用 MongoDB 数据库,可以通过官方的 mongodb 驱动或更高级的 mongoose ORM 工具与 MongoDB 进行交互
使用npm安装 mongoose 依赖:
npm install mongoose创建数据库的连接:
import mongoose from 'mongoose';
const mongoURI = 'mongodb://localhost:27017/test_db'; // 本地 MongoDB 地址
mongoose.connect(mongoURI, { useNewUrlParser: true, useUnifiedTopology: true })
.then(() => console.log('成功连接到 MongoDB 数据库'))
.catch(err => console.error('连接 MongoDB 失败:', err));定义数据Schema和Model:
const userSchema = new mongoose.Schema({
name: { type: String, required: true },
email: { type: String, required: true },
age: { type: Number, default: 0 },
}, { timestamps: true });
const User = mongoose.model('User', userSchema);简单的增删改查:
// 查询数据
const users = await User.find();
const user = await User.findById(req.params.id);
// 插入数据
const newUser = new User(req.body);
const savedUser = await newUser.save();
// 更新数据
const updatedUser = await User.findByIdAndUpdate(req.params.id, req.body, { new: true });
// 删除数据
const deletedUser = await User.findByIdAndDelete(req.params.id);环境变量
在 NodeJS 中,环境变量是一种重要的配置管理方式,用于将应用程序的运行环境与代码逻辑解耦。通过使用环境变量,可以在开发、测试和生产环境之间灵活地切换配置,例如数据库连接信息、API 密钥、端口号等敏感或动态配置
NodeJS 提供了内置的 process.env 对象,用于访问环境变量。这种机制不仅提高了代码的安全性和灵活性,还减少了硬编码的风险,便于应用的部署与管理。在实践中,结合 .env 文件和环境变量加载库(如 dotenv),可以轻松实现环境变量的管理和使用,满足不同场景的需求
命令行
NodeJS支持在命令行上直接传递环境变量:
NODE_ENV=production node server.js读取环境变量信息:
console.log(process.env.NODE_ENV); // productiondotenv
上面命令行的方式通常会在调试或者开发阶段简单实用,对于大型的项目还是要使用文件来管理复杂的配置,使用 dotenv 可以有效的管理配置
创建env文件:
PORT=3000
PUBLIC_PATH=/app
AUTHOR=ihengshuai在NodeJS中使用:
import dotenv from "dotenv";
const config = dotenv.config({
path: "./.env",
});
console.log(process.env.PORT, config);错误捕获
NodeJS中有2类重要的全局错误捕获事件unhandledRejection、uncaughtException:
- unhandledRejection:用来捕获异步程序没有捕获的错误,如promsie、async运行中产生的错误
- uncaughtException:用来捕获同步代码中没有被捕获的错误
来看下面一段简单的演示:
// 抛出异步错误
Promise.reject('异步错误');
process.on('unhandledRejection', (reason, p) => {
console.log('Unhandled Rejection at: Promise', p, 'reason:', reason);
// 抛出同步错误
throw new Error('同步错误');
});
process.on('uncaughtException', (error, origin) => {
// origin: "uncaughtException" | "unhandledRejection";
console.log('uncaughtException', error);
})除此之外很多模块都有对应的错误处理方式,如监听流的错误stream.on(error)等等,开发者使用时可以翻阅文档结合场景使用
SSR应用
node经常被作为SSR服务器使用,基于前端强大的生态效应,不同框架与NodeJS集成的ssr渲染也非常简单,这里不详细展开。你若对此感兴趣,可选择下方文档阅读实践:
Docker镜像
大部分公司都已经用上了云原生的企业架构方式,而容器化是云原生的重要组成部分,那么NodeJS应用如何构建成docker镜像呢
FROM node:18.19.0-alpine3.19
### 此配置文件只做演示
### 可以依赖作为基础镜像,在ci打包后拿到产物发布镜像在k8s中
WORKDIR /app
# 设置apk aliyun源
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories
RUN apk add --no-cache --update python3 make g++ \
&& apk add --no-cache --update nodejs=16.19.0-r0 yarn=1.22.10-r0 \
&& rm -rf /var/cache/apk/*
COPY src client
COPY public public
COPY .env.production .env.production
COPY index.html index.html
COPY nest-cli.json nest-cli.json
COPY package.json package.json
COPY tsconfig.json tsconfig.json
COPY tsconfig.build.json tsconfig.build.json
COPY vite.config.ts vite.config.ts
COPY ecosystem.config.js ecosystem.config.js
RUN npm install --registry=https://registry.npm.taobao.org && npm run build
RUN npm install pm2 -g
ENTRYPOINT ["pm2-runtime", "start", "ecosystem.config.js", "--env", "production"]关于docker镜像构建更详细的内容以及注意事项可以阅读往期文章 使用Dockerfile构建镜像
部署
小贴士
这里的部署仅是生产环境如何运行应用,不包含发布的其他流程
使用node filename可以运行应用程序,但可能一些运行时错误、内存泄漏等问题会造成应用崩溃,因此使用一个专业的工具最为合适
目前常见的部署工具为 pm2,它是一个守护程序进程管理器,它将帮助您管理和保持应用程序在线。开始使用PM2很简单,可作为简单而直观的CLI提供,可通过npm安装
# 安装到全局
npm install pm2 -g
# 简单部署脚本
pms start app.js --name test_deploy部署后的应用可以通过下面一些命令管理:
# 重启应用,平滑重启,不会造成中断
pm2 reload app_name
# 重启应用(完全停止后重启)
pm2 restart app_name
# 停止应用
pm2 stop app_name
# 删除应用
pm2 delete app_name除此之外你还可以查看应用的运行情况:
# 列出所有的应用
pm2 ls
# 所有日志
pm2 logs [app_name] [-f]不过只使用上面的这种方式部署感觉和直接使用node运行应用的方式大差不差,虽然可以通过一些参数对内存、重启等健康检查,但完全是个黑箱操作,而生产环境通常都会使用配置文件来部署
执行pm2 init 或 pm2 ecosystem 生成 配置文件ecosystem.config.js:
module.exports = {
apps: [
{
name: "app1",
script: "./app.js",
env_production: {
NODE_ENV: "production",
},
env_development: {
NODE_ENV: "development",
},
},
],
};然后在终端执行:
pm2 start ecosystem.config.js --env production该配置文件还支持很多有用的属性
| Field | Type | Example | Description |
|---|---|---|---|
| name | (string) | “my-api” | 应用程序别名 |
| script | (string) | ”./api/app.js” | 应用程序入口 |
| cwd | (string) | “/var/www/” | 应用程序被执行的根目录 |
| args | (string) | “-a 13 -b 12” | 所有的参数 |
| interpreter | (string) | “/usr/bin/python” | 可执行的解释器路径,默认为node |
| interpreter_args | (string) | ”–harmony” | 传给解释器的参数 |
| node_args | (string) | 同上 | |
| instances | number | -1 | 程序启动的实例数目 |
| exec_mode | string | “cluster” | 启动程序的模式cluster/fork,默认fork |
| watch | boolean or [] | true | 启用监视、重启特性,如果文件改变应用将会平滑重启 |
| ignore_watch | list | ['[/\]./', 'node_modules'] | 忽略监视的列表支持正则 |
| max_memory_restart | string | “150M” | 应用内存最大多少重启 |
| env | object | {“NODE_ENV”: “development”, “ID”: “42”} | 程序启动时自动注入 |
| env_ | object | {“NODE_ENV”: “production”, “ID”: “89”} | 运行时根据--env xxx来匹配对应的配置然后注入 |
还有很多有用配置建议阅读官方文档
感谢支持



