玩转NodeJS多进程与多线程
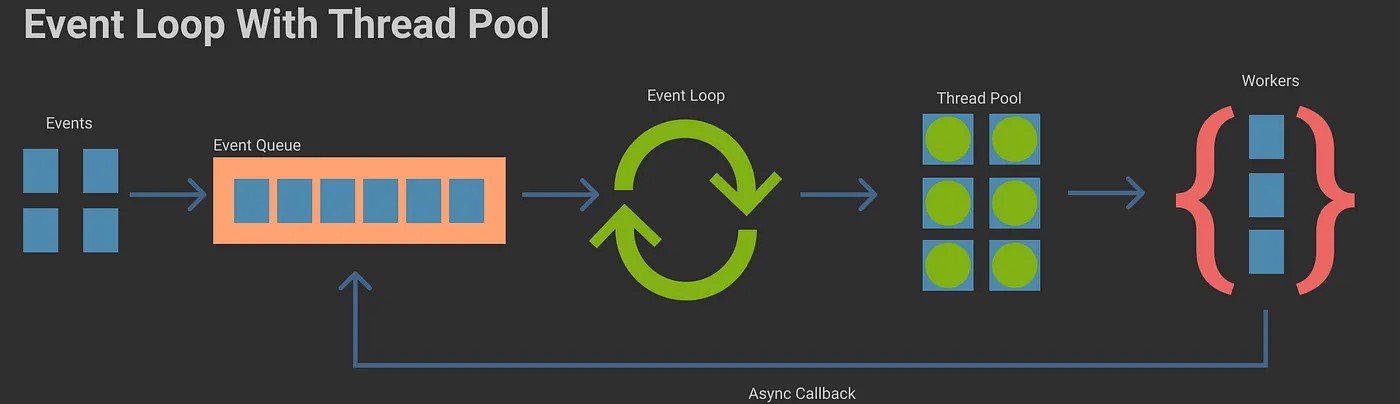
在现代Web应用和后端服务开发中,性能与并发处理能力是系统稳定运行的核心指标之一。作为一款以事件驱动、非阻塞 I/O 为基础的运行时环境,Node.js一直以其高效的单线程模型闻名。然而,单线程也带来了显而易见的局限性,特别是在处理 CPU 密集型任务或需要高并发的场景时,单线程可能无法充分发挥多核 CPU 的性能优势。为了解决这一问题,Node.js 提供了多进程和多线程的能力,以补足单线程模型的不足
多进程和多线程的引入,不仅让开发者可以充分利用多核硬件的并行计算能力,还为任务隔离、资源优化和高性能服务提供了更多可能性。然而,这两种并发处理方式各有特点,在实际应用中需要结合业务需求进行选择和优化。本篇文章将由浅入深带您深入探讨 Node.js 的多进程与多线程机制,从基础概念到实践应用,帮助您更好地理解和应用这些强大的工具
小贴士
文章中涉及到的代码示例你都可以从 这里查看 ,若对你有用还望点赞支持
NodeJS单线程模型
相信很多开发者都知道或者听过NodeJS是个单线程应用,那为什么还说它能高性能的处理并发任务呢❓不知道有没有开发者提出过质疑(至少了解js的机制或者其他语言),反正我本人是带着疑问的、
其实,NodeJS在运行时并非就只有一个线程在工作,通常所说的单线程是指js程序的运行/执行(可以认为是js的主线程执行),而背后的libuv内部会提供线程池来协助完成其他IO操作等其他任务,最终由EventLoop(调度中心)来调度执行
事件循环
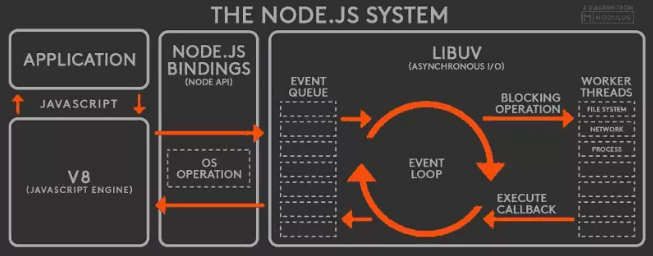
虽然 Node.js 采用了单线程模型,但基于事件驱动通过事件循环(Event Loop)机制可以高效地处理 I/O 操作和并发任务。在这种模型下,所有代码都运行在同一个线程中,避免了多线程编程中常见的死锁和线程同步问题。这种设计非常适合处理大量 I/O 密集型任务,如文件读写、网络请求等,能够在单线程中实现高并发性能
这里对于NodeJS的EventLoop不做深度展开了,感兴趣的可以阅读我的往期文章 NodeJS事件循环机制
为什么需要多进程与多线程
既然NodeJS采用事件驱动机制可以提供并发性能为啥还需要多进程与多线程呢。首先我们要知道EventLoop大多数都是服务于IO操作的,这些操作可以通过异步回调的方式执行计算结果,但对于JS的运行往往都在那个单线程上,如果一个业务逻辑涉及到CPU密集的同步计算,就会阻塞后面的请求,那并发性就更不用提了
来看一段这样的代码:
const express = require("express");
const app = express();
function runCompute() {
for (let i = 0; i < 10e9; i++) { /* do nothing */ }
}
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
runCompute();
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});程序表达的意思很简单,就是在请求服务器时用runCompute来模拟一段高密集的计算,然后看看请求的打印时间。启动服务器后,同时发起2个请求,我们看看他的日志情况:
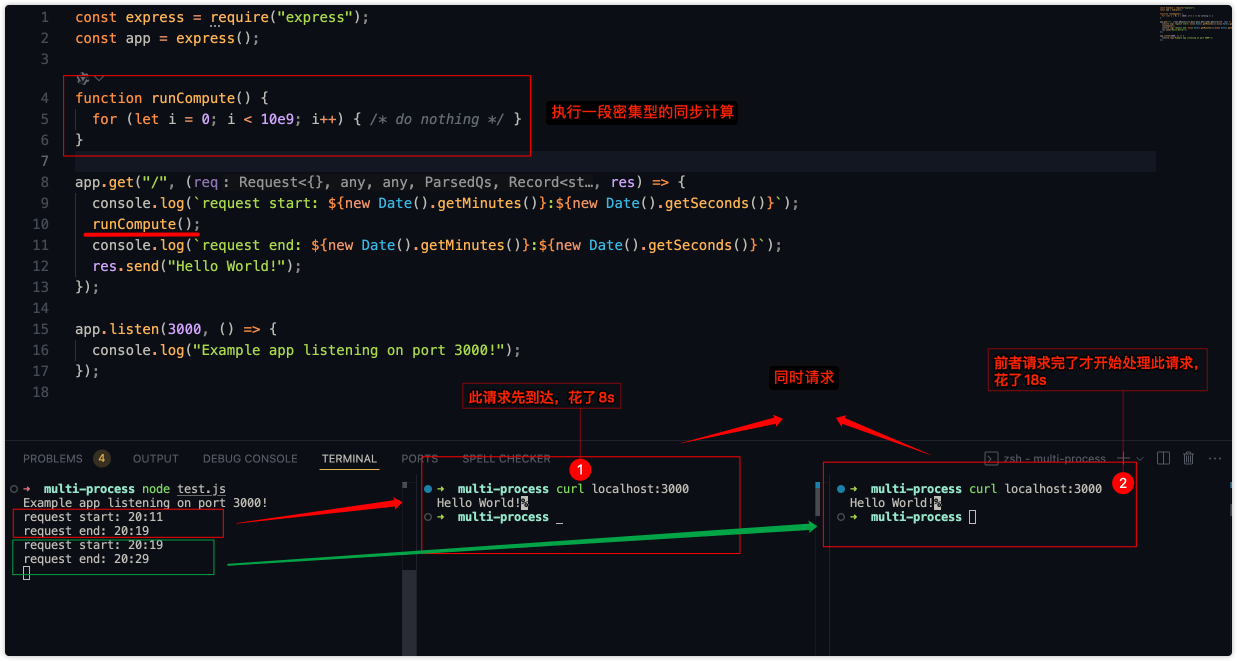
虽然2个请求是同时发出的,但从打印的时间很明显可以看出服务器只能同时处理一个请求,当前面的请求处理完后才开始处理后面的请求。到这里应该知道明白点为什么会这样了吧,虽然NodeJS有很出色的并发性能但那都是基于异步、IO操作,当遇到同步密集型的计算就招架不住了😱
总体来看NodeJS的单线程模型存在以下几方面的问题:
CPU利用率低:NodeJS是单线程模型在单核机器上完全可以正常执行,而如今大多数机器都是多核的,线程是CPU调度的基本单位,可以通过新开线程或进程的方式提高计算的效率,提高CPU的利用率,避免NodeJS单线程情况下CPU的资源浪费同步阻塞问题:虽然NodeJS的单线程借助事件循环巧妙通过异步回调的机制解决了并发问题,但始终无法避免同步阻塞问题,尤其是那种CPU密集型的计算性能及稳定:单线程的程序在发生不确定的错误后很快就会挂掉,这对于一个稳定可靠的应用程序是致命的
使用多进程形式稍微改造下上面的代码:
// cpu-compute.js
function runCompute() {
for (let i = 0; i < 10e9; i++) { /* do nothing */ }
}
process.on('message', () => {
runCompute();
process.send('done');
process.exit(0);
});
// cpu-compute-main.js
const express = require("express");
const app = express();
const child_process = require("node:child_process");
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
const child = child_process.fork("./cpu-compute.js");
child.send("start");
child.on("message", () => {
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});再看看执行情况,很明显程序能够同时处理请求了,请求都之花了9s,并且没有造成阻塞;这就是使用多核CPU计算的优势

接下来我们看看如何使用多进程线程来提高程序的并发性能,以及他的通常使用场景
提高并发的措施
从上面内容中我们也清楚了单单靠异步的事件驱动是不能代表高效率的并发任务的,这里我们先来列出在node中还有哪些能够提高并发性的措施
异步IO:这是大家都烂于心的老东家,通过非阻塞的异步IO如:文件读写、数据库访问等等,通过事件循环实现并发多进程/Cluster模式:通过多进程方式充分利用多核 CPU 的能力,从而实现并发处理多线程模式:通过多线程方式处理CPU密集型任务,避免阻塞后续任务,提高程序并发性
多进程
进程是计算机程序的一次运行实例,它是操作系统进行资源分配和调度的基本单位。一个进程通常包括代码(可执行程序)、所使用的数据、系统分配的资源(如内存、文件句柄等)以及正在运行时的线程信息。进程的存在使得程序可以在操作系统中独立运行,并与其他程序隔离开来
运行一个NodeJS服务,系统就会创建一个进程:
const { createServer } = require("node:http");
process.title = '大卫talk';
createServer().listen(3000, () => console.log("server start on 3000 port."));
进程是操作系统中不可或缺的基础组件,它的独立性和隔离性为程序的稳定运行提供了保障。通过合理使用进程机制,我们可以更高效地利用系统资源,提升程序的性能和可靠性
创建多进程方式
Node.js 提供了几种方式来创建和管理多进程,其中最常用的是通过 child_process 模块实现
Node.js 的 child_process 模块提供了四种主要的方法API,用于创建和控制子进程。通过它,主进程可以生成子进程,执行指定任务,并与子进程进行通信,不同的方法适用于不同的场景:
spawn:启动新的子进程来执行命令exec运行 shell 命令并将结果返回给回调函数execFile:直接执行指定的可执行文件,不使用 shellfork:用于派生子进程,专门适合运行 Node.js 脚本
spawn
spawn用于执行命令脚本,通常用作执行长时间运行的命令并实时处理输出流,通过流(stdout、stderr)返回输出,没有内存限制适合处理大量数据
const { spawn } = require("node:child_process");
const command = spawn("ls", ['-a'], {});
command.stdout.pipe(process.stdout);
// 等价于
// command.stdout.on("data", (d) => console.log(Buffer.from(d).toString()));spawn是异步执行函数不会阻塞EventLoop,而spawnSync则是它的同步版本;当执行开启子进程后,父子进程的stdin/stdout流会建立连接,子进程数据以流的形式发送给父进程,并且是实时的一段段同步
有一些重要的参数需要读者了解下,这些参数部分方法都是通用的
stdio:用来设置如何处理子进程的输入输出,默认为pipe,也就是父子通用流管道来传递数据pipe:父子进程通过流管道进行数据流的传递overlapped:与pipe类似,只是句柄上设置了file_flag_overlapperlapped标志ignore:父进程忽略子进程的输入输出流inherit:继承父进程的标准输入输出流,等同于child.pipe(process.stdout)
detached:当此值为true时,子进程将不会在父进程退出时而退出,并且有自己的终端窗口;默认情况下父进程会等待子进程,直到子进程退出,如果不需要父进程等待,执行child.unref()即可,这样子进程成孤儿了
exec
小贴士
不启用shell解析直接通过操作系统执行命令效率更搞,但shell相关的命令符可能不支持,如:>>、|等等
exec与spawn类似,只不过exec有数据上线1MB,所以只能处理数据量比较简单的的指令,并且会通过系统的shell进行解析执行;execSync是它的同步版本
const { exec } = require("node:child_process");
exec("ls -a", (error, stdout, stderr) => {
console.log(stdout);
});exec支持传入回调函数的方式来接受子进程的状态,数据以字符串或buffer的形式一次性传递,如果超过内存限制进程就会立即结束
它也支持传入类似的参数,假如这里我们限制他的最高限制为1:
exec("ls -a", { maxBuffer: 1 }, (error, stdout, stderr) => {
console.log(stdout);
});输出的结果仅仅是一个.,然后程序就立马结束
execFile
execFile与exec不同的是,它是通过可执行文件来执行命令,而不是直接传递命令参数
const { execFile } = require("node:child_process");
const child = execFile("node", ["./node-bin.js"]);
child.stdout.pipe(process.stdout);由于它不会通过shell来解析,直接执行指定的可执行文件,性能优势更加;execFileSync是它的同步版本
fork
fork是基于spawn封装的一种用于创建子进程的高级方法,通常用于运行独立的 Node.js 脚本,子进程与主进程之间有一个内置的、双向的 IPC(进程间通信)通道,通过 message 事件发送和接收消息
WARNING
每个进程有它自己的内存、v8实例,如果开启过多的子进程会消耗更多的资源,通常都会根据实际情况≤CPU核心数
我们简单尝试下fork的使用方法:
先定义一个父进程:
const { fork } = require("node:child_process");
const child = fork("./fork-child.js");
child.send("hello child!");
child.on("message", (msg) => {
console.log("child message:", msg);
});
child.on("exit", () => {
console.log("子进程已退出!");
});再定义子进程:
process.on("message", (data) => {
console.log("from parent: ", data);
process.send("hello parent");
process.exit(0);
});现在直接运行父进程就可以查看效果了
由于进程都是一个NodeJS实例,都会继承Events,在建立IPC通道后,父子进程通过事件的形式进行数据传输。和平时用的事件或方法都类似,如:message、send、exit、error等等,读者可以查阅官方文档
进程通信方式
上文中也向读者介绍了进程操作系统进行资源分配和调度的基本单位,每个进程独享一块内存空间,进程间是无法访问对方的数据的,那进程之间又是通过什么方式来通信的呢?有好多种方式(可查看操作系统进程通信章节)。下面我们简单列举说明:
管道/命名管道:一个进程将内容输入到管道中,另一个进程从管道中取出,管道又分为匿名管道和命名管道(FIFO),在UNIX中一切都是文件,管道也不列外。前者存在于内存中、后者则是物理磁盘,这里简单提一下
# 匿名管道
➜ cat accept.log | grep usword消息队列:通过内核中的消息链表进行数据的存取,但有大小限制和数据拷贝开销共享内存:目前的操作系统都采用了虚拟内存管理,每个进程中的虚拟地址块可以映射到同一个物理地址,这样数据修改直接就可以拿到了,但此方式会有冲突风险信号量:主要解决共享内存的冲突风险,通过信号量实现进程间的互斥,好比进程加锁一样信号:通过信号的方式通知进程,比如kill、ctrlC等等套接字(Socket):UNIX Socket 套接字通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信;通信前两端都会创建socket,然后返回套接字描述符,两端连接后通过socket首发数据(具体查看socket通信原理)
我们平时使用http请求都是基于TCP套接字进行通信的,比如在node中创建一个http服务,底层还是调用net进行tcp套接字的创建
NodeJS中内置IPC通信
在NodeJS中使用IPC通信非常简单,提供child_process的fork方式内置使用ipc通信
// parent.js
const { fork } = require("node:child_process");
const child = fork("./fork-child.js");
child.send("hello child!");
child.on("message", (msg) => {
console.log("child message:", msg);
});
child.on("exit", () => {
console.log("子进程已退出!");
});
// child.js
process.on("message", (data) => {
console.log("from parent: ", data);
process.send("hello parent");
process.exit(0);
});NodeJS中自定义管道通信
除了使用socket、ipc通信外,我们还可以使用管道方式进行通信,这里我们来尝试下如何自定义管道:
const { createServer, connect } = require("node:net")
// 定义管道文件所在路径(管道即文件)
const filePath = './unix.sock';
// server
const server = createServer(socket => {
socket.on("data", data => {
socket.write(data)
server.close();
})
})
// listen(path: string, listeningListener?: () => void): this;
.listen(filePath)
// client
const client = connect(filePath)
client.on('connect', () => client.write('hello server'));
client.on("data", data => {
console.log(data.toString())
client.end();
})运行上面的代码后如期执行:

多进程模式
上文我们也了解到单进程架构无法利用多核CPU的优势,那么使用多进程就可以充分发挥cpu优势,提高程序的性能。下面是一段常见的多进程TCP服务架构
const { fork } = require('node:child_process');
const net = require('node:net');
const http = require('node:http')
const os = require('node:os');
const cpus = os.cpus().length;
if (process.argv[2] !== 'worker') {
const workers = [];
// 创建 TCP 服务器
const server = net.createServer();
server.listen(8000, () => {
console.log('TCP 服务器已启动,端口 8000');
// 创建工作进程并传递服务器句柄
for (let i = 0; i < cpus; i++) {
const worker = fork(__filename, ['worker']);
workers.push(worker);
// 将服务器句柄发送给子进程
worker.send('server', server);
}
});
} else {
const childServer = http.createServer((req, res) => res.end(`hello client, from: ${process.pid}`))
process.on('message', (msg, socket) => {
if (msg === 'server') {
// 子进程接收服务器句柄
socket.on('connection', (socket) => {
childServer.emit('connection', socket)
});
}
});
}主进程创建TCP连接拿到socket通信描述符(也就是句柄)后,根据cpu的核数创建多个子进程,并将句柄传递给每个进程,由子进程创建和客户端的tcp连接,这样就做到了服务端监听同一个端口却同时运行多个tcp服务,同时处理请求返回给客户端,提高程序的性能
多进程优缺点
多进程是一种通过操作系统将任务分配到多个独立进程运行的并发模型。每个进程都有独立的资源分配,如内存空间、文件句柄等。这种模式常用于提高应用程序的性能和容错能力
多进程的优点
- 建多个独立进程,并分布在不同核心上运行,实现真正的并行处理,从而提升性能
- 由于每个进程运行在独立的内存空间中,一个进程崩溃不会直接影响其他进程或主进程。这种隔离性提高了系统的稳定性
- 多进程机制由操作系统管理,与具体编程语言无关。因此,应用程序可以通过多进程实现跨语言调用和跨平台运行
- 多进程在处理大量独立请求时表现优越,尤其是在 Web 服务器、爬虫、批量数据处理等场景中,可以显著提高吞吐量
多进程的缺点
- 当进程数较多时,资源开销会显著增加
- 进程之间不能直接共享内存,需要通过 IPC(进程间通信)机制,如管道、信号、消息队列、Socket 等。这些机制相对复杂且可能带来性能开销
- 进程的启动和销毁涉及操作系统的系统调用,成本较高。同时,进程切换(Context Switch)需要保存和恢复资源状态,增加了延迟
多线程
与进程不同的是线程是进程一个基本计算单位,或者说是一条指令,进程可以创建多个线程,线程可以同时工作。同一个进程内多个线程之间共享代码段、数据、文件等资源,但每个线程都有一套独立的寄存器和栈
既然有了多进程为啥还要创建多个线程呢❓从上文也可以知道进程的缺点就是资源占用过多、数据不共享等等,所以可以创建多个线程来提升计算性能
如何创建多线程
NodeJS从 v10.5.0 开始引入了 worker_threads 模块,提供了创建独立线程的能力,每个线程都有自己的事件循环和内存空间,可以在主线程中运行特定任务,同时通过消息传递实现通信
上面在说明为什么需要多进程时演示了一段CPU密集任务的http请求,然后使用fork子进程的形式提高了cpu的利用率;然而进程的性能开销比较大,相对而言线程更友好,来把上面代码用线程的方式改造下:
创建主线程:
/** 通过多线程方式解决CPU密集操作 */
const express = require("express");
const app = express();
const { Worker } = require("node:worker_threads");
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
const worker = new Worker("./thread-worker.js", { workerData: { count: 10e9 } });
worker.postMessage("start");
worker.on("message", () => {
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});创建worker线程用于执行密集型任务:
const { workerData, parentPort } = require("node:worker_threads");
// 从主线程拿到最大数字
const { count } = workerData;
function runCompute() {
for (let i = 0; i < count; i++) { /* do nothing */ }
}
runCompute();
parentPort.postMessage("done");启动上面的主线程http服务后,我们再次同时发起2次http请求,查看请求结果

以下是在发起http请求前后的node线程数的变化,可以看出总共发了2次请求创建2个线程

worker_threads有很多重要的属性和方法,这里不详细展开具体查看文档即可
线程之间通信方式
学会创建线程后如何进行数据通信才是关键❓node也提供了多种方式:事件、MessageChannel、BroadcastChannel、workData等方式,其中MessageChannel、BroadcastChannel这些前端开发者应该也很熟悉,它们在浏览器端也经常使用
基于worker自身的事件:创建worker后可以基于事件进行通信
const { workerData, parentPort } = require("node:worker_threads");
// 主线程
worker.postMessage
woker.on('message')
// 子线程
parentPort.postMessageMessageChannel:使用MessageChannel其实和worker事件类似,不同的是它创建的双向的通信支持其他线程之间通信,不会局限于主线程和子线程
// 主线程
const express = require("express");
const app = express();
const { Worker, MessageChannel } = require("node:worker_threads");
process.title = "thread-main";
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
const subChannel = new MessageChannel();
const worker = new Worker("./thread-worker-messagechannel.js", { workerData: { count: 10e9 } });
worker.postMessage({ port: subChannel.port1 }, [subChannel.port1]);
subChannel.port2.on("message", () => {
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});
// 子线程
const { workerData, parentPort } = require("node:worker_threads");
const { count } = workerData;
function runCompute() {
for (let i = 0; i < count; i++) { /* do nothing */ }
}
parentPort.once("message", ({ port: messagePort }) => {
runCompute();
messagePort.postMessage("done");
});BroadcastChannel:不同的线程通过一个共享的频道名称发送和接收消息,而无需显式地引用彼此,简化了多线程通信的实现;消息广播给所有监听的线程,适合一对多通信
// 主线程
const express = require("express");
const app = express();
const { Worker, BroadcastChannel } = require("node:worker_threads");
process.title = "thread-main";
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
// 创建指定命名的广播通道
const channel = new BroadcastChannel('broadcast_channel');
new Worker("./thread-worker-broadcast.js", { workerData: { count: 10e9 } });
channel.postMessage("start");
channel.onmessage = () => {
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
}
});
// 子线程
const { workerData, BroadcastChannel } = require("node:worker_threads");
const channel = new BroadcastChannel('broadcast_channel'); // 拿到同名的广播通道
const { count } = workerData;
function runCompute() {
for (let i = 0; i < count; i++) { /* do nothing */ }
}
runCompute();
channel.postMessage("done");内存共享:线程在同一个进程中是共享内存数据的,那么在node中可以使用SharedArrayBuffer和Atomics实现线程之间的内存共享,而无需通过消息传递
// 主线程
const { Worker } = require("node:worker_threads")
const sharedBuffer = new SharedArrayBuffer(4); // 创建共享内存
const sharedArray = new Int32Array(sharedBuffer);
const worker = new Worker('./thread-worker-shared.js', { workerData: sharedBuffer });
console.log("子线程操作前的值:", sharedArray[0]);
worker.on('message', () => {
console.log("子线程操作后的值:", sharedArray[0]);
});
// 子线程
const { parentPort, workerData } = require("node:worker_threads");
const sharedArray = new Int32Array(workerData);
for (let i = 0; i < 1000; i++) {
Atomics.add(sharedArray, 0, 1); // 原子操作,确保线程安全
}
parentPort.postMessage("done");执行后的结果:
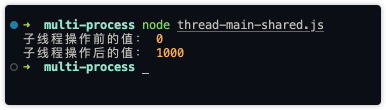
多线程优缺点
多线程是一种通过在一个进程中创建多个执行线程来并发处理任务的技术。它广泛应用于多核处理器的现代计算中,以提高程序性能和响应速度。然而,多线程也带来了一些复杂性和问题
多线程优点
- 多线程能够让程序充分利用多核 CPU 的性能,每个线程可以分配到不同的 CPU 核心上并行运行,从而提升程序的执行效率
- 多线程允许主线程处理用户界面或响应事件,而将耗时操作交给工作线程处理,从而提升应用的响应能力
- 多线程使得将复杂任务拆分为多个独立子任务变得更容易。每个线程可以独立运行,彼此协作完成大任务
多线程缺点
- 访问共享资源时,如果没有正确的同步机制,可能会导致 数据竞争(Race Condition),即多个线程同时修改数据导致结果不可预测
- 当两个或多个线程相互等待对方释放资源时,会产生 死锁(Deadlock),导致线程无法继续运行,程序陷入僵局
- 多线程程序中,错误往往是 间歇性 或 难以复现 的,因为线程调度和执行顺序不可预测。这增加了调试和维护的难度
多进程与多线程对比
多进程和多线程是实现并发和并行的重要工具。它们都有各自的优缺点,并适用于不同的场景。以下从定义、工作机制、适用场景、优缺点等方面进行总结和对比
| 特性 | 多进程 | 多线程 |
|---|---|---|
| 内存和资源隔离 | 每个进程有独立的内存和系统资源 | 线程共享进程的内存和资源 |
| 调度单位 | 由操作系统调度,粒度较粗,进程切换开销较大 | 由操作系统调度,粒度较细,线程切换开销较小 |
| 通信方式 | 通过进程间通信(IPC),如管道、Socket、消息队列等 | 通过共享内存和同步机制(如锁、信号量等) |
| 启动速度 | 进程创建需要初始化独立资源,启动速度较慢 | 线程创建无需独立分配资源,启动速度较快 |
| 崩溃影响 | 单个进程崩溃不会影响其他进程 | 单个线程崩溃可能导致整个进程终止 |
NodeJS集群
Node.js 是单线程的运行时,默认通过事件循环处理非阻塞 I/O,这种模型虽然高效,但会受限于单线程性能,尤其在高并发或多核 CPU 的环境下无法充分利用系统资源。为了解决这一问题,Node.js 提供了 集群(Cluster) 模块,用于实现多进程架构,在多核环境中提升性能
const cluster = require("node:cluster");
const http = require("node:http");
const os = require("node:os");
if (cluster.isMaster) {
// 主进程逻辑
const numCPUs = os.cpus().length;
console.log(`主进程 ${process.pid} 正在运行`);
// 创建与 CPU 核心数量相等的工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听工作进程退出事件
cluster.on("exit", (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
// 可选择性地重启工作进程
cluster.fork();
});
} else {
// 工作进程逻辑
http
.createServer((req, res) => {
res.writeHead(200);
res.end(`你好!工作进程:${process.pid}`);
})
.listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}运行程序后多次请求服务,会发现处理请求的进程会一直发生变化,而这背后正是cluster的负载均衡算法支配的

如果读者从本篇文章的多进程章节看过来的话,对于集群的代码实现也应该有所理解
小贴士
通过child_process也可以做一个类似cluster集群架构,在上面的示例补充负载均衡策略、子进程的管理措施基本上就可以满足了。而cluster让进程间的管理更加简单
正如前面使用child_process创建的多进程应用,cluster主进程负责管理和维护工作进程,包括分发任务、监听进程状态、处理重启等,在处理请求时主进程通过负载均衡算法指定某个子进程来处理客户端的请求;主进程与工作进程之间通过 IPC(进程间通信) 管道进行通信。主进程可以发送消息给工作进程,工作进程也可以通过消息向主进程汇报状态
cluster还有很多重要的属性和方法,都比较容易懂读者可自行查阅文档。在这种集群模式下编写代码区别不大,最多就是通过来判断主进程和子进程进行区分
PM2 也提供集群部署模式,其背后的原理也是cluster
对于高并发量的实际应用也不可能在一台机器上部署多个服务,机器挂掉后所有的服务都无法访问了,这种还是有很大缺陷的。通常都会准备很多机器节点,每个节点都会部署应用,然后在网关做负载均衡,在往期文章 Nginx实战 实现过高可用部署方案
总结
在 Node.js 的运行环境中,多进程、多线程与集群技术为提升性能和扩展性提供了强大的支持。多进程通过为每个任务创建独立的进程,充分利用多核 CPU,实现高并发与容错能力,但资源开销较大。多线程则通过共享内存空间,在计算密集型任务中提高性能,适合处理 I/O 和 CPU 密集的混合任务。集群模块结合多进程,允许多个进程共享同一服务器端口,通过负载均衡优化请求处理,进一步提高性能和稳定性。这些机制的合理使用,可以帮助开发者构建高效、可扩展的 Node.js 应用,在现代分布式系统中表现尤为突出
感谢支持



