NodeJS入门指南
NodeJS入门教程将带你快速掌握 Node.js ,从基础的安装与环境配置开始,到核心模块的使用。无论你是初学者还是有经验的前端开发者,通过学习 Node.js,你都将拓宽技术视野,构建更全面的开发能力
小贴士
文章中涉及到的代码示例你都可以从 这里查看 ,若对你有用还望点赞支持
概念
NodeJS是一个基于 V8引擎 构建的 JavaScript 运行时,它让开发者可以使用 JavaScript 编写服务端代码,从而实现前后端统一的开发语言。自问世以来,Node.js 已成为构建现代 Web
它也是一个开源的、跨平台的 JavaScript 运行时环境,专为构建高性能、高并发的服务器端应用程序而设计。通过非阻塞 I/O 和事件驱动架构,使得开发者能够高效处理网络请求,并构建具有极佳扩展性和性能的应用
特点
Node.js应用程序在一个进程中运行,而无需为每个请求创建新线程。在其标准库中提供了一组异步的I/O规范,以防止阻塞JS;通常,Node.js中的库都是使用非阻止范式编写的
在执行IO操作时如:读取文件、访问数据库等等,不会阻塞线程和浪费CPU,只会在响应返回时恢复操作,这样Node通过一个进程就可以处理成千上万的请求了,这也是NodeJS高效的原因,但同时也是bug出现的导火索
由于NodeJS也是JS语言,他可以让前端开发者低成本的学习它,从而更快的搭建服务器。简单的可以总结为以下几种:
事件驱动与非阻塞 I/O:单线程事件循环机制,高效处理大量并发请求,非阻塞 I/O 模型使其适合处理 I/O 密集型任务跨平台支持:支持 Windows、macOS 和多种 Linux 发行版,适合各种开发环境和部署需求强大的生态系统:拥有世界上最大的包管理器(npm),提供数百万个模块和工具,极大地提升了开发效率前后端统一语言:开发者可以使用同一种语言(JavaScript)构建前后端应用,降低学习成本,提高开发协作效率
安装与配置
NodeJS支持多种方式的安装,比如:客户端安装(傻瓜式)、包管理器、二进制、源代码等等,但小编最推荐的还是包管理器方式安装,这里我们只介绍前两种方式
客户端傻瓜式安装
客户端傻瓜式安装非常简单,直接打开NodeJS官方安装地址,根据自己的系统选择对应的处理器和想要的Node版本,最后点击下方的下载按钮就可以下载了

下载后直接双击安装包,根据提示一直下一步就可以了,安装成功后打开终端,检测是否安装成功:

小贴士
若安装后成功后提示找不到相关命令,请重启终端或者配置环境变量;此种方式对于使用多版本NodeJS不是很友好
包管理器安装
上面使用客户端安装的方式其实我并不是很推荐,因为它无法做到多版本的轻松切换。当前NodeJS版本迭代的还是比较快的,由于历史原因,可能很多项目的版本都发生了大的跨度,如果要切换一次版本就要手动安装一次会变得非常麻烦,这时候包管理器就登场了
什么是包管理器❓它主要就是系统化的管理NodeJS的,使用包管理器你可以轻松安装想要使用的版本,当然你可以在本地轻松的进行版本的切换,这相对于手动安装更胜一筹
那么如何使用它呢。包管理器并不只有一种,常见的有nvm、n、fnm、docker等等,这里我们介绍前2种
- nvm 是一个传统稳定的包管理器,支持常见的系统,拥有大量的用户,使用体验也很好,推荐Windows用户使用。使用它需要先安装,详细步骤你可以阅读我的往期文章「NVM切换Node版本」
➜ nvm version
1.1.8
➜ nvm list
➜ nvm use 版本号
➜ nvm install 版本号- n 也是一个优秀的包管理,比较精简、轻巧好用,支持MacOS、Linux,不支持Windows,非常推荐在Mac上使用它来管理Node,本人也一直在使用:
➜ n --version
v9.0.1
➜ n list
node/14.18.0
node/16.19.0
node/18.10.0
node/20.12.2
➜ n # 输入n可以切换版本第一个NodeJS应用
使用NodeJS可以快速搭建一个web服务器,只需要简单的几行代码即可:
// http.js
const { createServer } = require("http");
const hostname = "127.0.0.1";
const port = 3000;
const server = createServer((req, res) => {
res.statusCode = 200;
res.setHeader("Content-Type", "text/plain");
res.end("Hello World");
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}`);
});将上述代码复制到编辑器中后,打开终端进入到当前文件所在目录,运行以下命令:
➜ node http.js
Server running at http://127.0.0.1:3000小贴士
若你还不知道怎么运行程序,可以先看下面的 命令行运行
接下来我们来验证下服务器是否正常,访问这个web服务器地址:
➜ curl http://127.0.0.1:3000
Hello World成功了‼️ 如期的返回Hello World文本,这正是我们代码中写的。使用NodeJS就是这么简单,快接着走下去了解更多吧
命令行
Node.js 提供了一个简单而强大的命令行工具,让开发者可以直接在终端中运行 JavaScript 代码,调试程序,或者执行文件
运行文件
小贴士
Shebang 是指在类 Unix 操作系统(如 Linux 和 macOS)中,脚本文件开头的特殊注释行,通常写作 #!,后面跟随解释器路径,用于指定运行脚本所需的解释器
通常最常用的使用node传递想要运行的文件名字后执行程序,比如你有一个程序的名字为app.js,你只需要执行:
➜ node app.js此种方式显示的告诉终端使用node来执行脚本,除此之外你还可以使用shebang注释将其嵌入到程序文件中,这样系统就可以根据注释来选择对应的解释器来执行程序了,此种方式也必须要赋予文件对应的可执行权限,这很重要:
#!/usr/bin/env node
// 业务代码...接着赋予文件可运行的权限:
➜ chmod u+x app.js当上面的一切准备完后就可以运行了,在终端直接输入对应的文件路径或名字即可
Node.js REPL
REPL代表Read - Evaluate - Print Loop,它是一种编程语言环境(基本上是一个控制台窗口),它接受单个表达式作为用户输入,并在执行后将结果返回给控制台。REPL会话提供了一种方便的方法来快速测试简单的JavaScript代码
打开终端输入node不带任何参数回车,就会开启一个REPL区域:
➜ node
Welcome to Node.js v18.10.0.
Type ".help" for more information.
>运行后你可以执行一些简单的JS代码,方便使用者快速测试
读取环境变量
小贴士
Process是一个内置模块,不需要导入就可以使用
Process 模块的env属性承载着所有的环境变量,用户手动设置的变量和系统变量都可以在内部找到
console.log(process.env.NODE_ENV);设置环境变量的方式有多种,最常见的就是:命令行传参、env文件
- 命令行传参:
➜ NODE_ENV=production node app.js- env文件:node20及以上版本支持
--env-file传入.env文件,程序可以访问内部设置的变量
➜ node --env-file .env app.js输入与输出
输入输出指的是和终端的交互,NodeJS可以输出内容到终端显示,同时也可以从终端读取输入的内容,此过程可以通过交互式无限进行下去
输出前端同学都比较熟悉:console
而输入NodeJS提供了 readline模块 执行此功能,从可读流(例如process.stdin流)中获取输入,该流在执行node.js程序中是终端输入,一次一行
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
rl.question(`What's your name?`, (name) => {
console.log(`Hi ${name}!`);
});
rl.on("line", (input) => {
console.log("You said:", input);
});
rl.on("close", () => console.log("Bye!"));运行后的效果:
模块化与模块加载
模块化是 Node.js 的核心特性之一,旨在实现代码的分离、复用和管理。Node本身包含很多内置的模块,开发者也可以按功能划分模块文件实现关注点分离,除此之外还可以使用包管理器引入第三方库文件模块
前端同学应该对于模块引入都不陌生,在前端通常使用import/export进行模块的导入导出,而NodeJS则使用require/exports规范进行的,接下来看看CommonJS概念吧
CommonJS
CommonJS 是一个模块化规范,最早由 JavaScript 社区提出,用于解决 JavaScript 在服务端开发中缺乏模块化机制的问题。Node.js 采用了 CommonJS 规范作为其模块系统,使得开发者可以轻松地将代码分割成独立的模块,并在模块之间共享功能
模块导出
CommonJS将每个文件都视为一个单独的模块,每个模块都有几个重要的变量如:require、module、exports等。被加载的模块是一个私有作用域,只有被导出的变量外部才可以访问到
在模块内可以使用module.exports和exports导出变量:
exports.username = 'ihengshuai';
module.exports = { age: 10 }而module.exports和exports是一个东西:
console.log(module.exports === exports); // true那么这两个有什么区别呢❓其实却别不大,最重要的就是导出时的规范:
exports不能直接以对象的形式导出,必须以一个个属性形式导出module.exports就比较自由了,你可以直接以对象的形式导出,或者一个个属性导出,对象导出必须在属性导出之前
为什么要这样做呢?不这样做会怎么样哩,我们来看下面一段代码:
// a.js
let count = 0;
function getCount() { return count; }
function setCount(value) { count = value; }
exports = {
count,
getCount,
setCount,
};
// b.js
const aModule = require("./a");
console.log(aModule.count); // undefined
aModule.setCount(); // 报错:setCount不是function
aModule.getCount(); // 报错:getCount不是function会什么会报错呢?而换成module.exports就不会有问题!要搞懂其内在原因还是要从源码看起
首先上面模块a代码会通过文件系统读取成字符串,然后经过编译后变成下面的结果:
// 模块a被编译后的代码
function ƒ(exports, require, module, __filename, __dirname) {
let count = 0;
function getCount() { return count; }
function setCount(value) { count = value; }
module.exports = {
count,
getCount,
setCount,
};
}对,你的源码会被嵌入到一个function中!在接着讲下去之前,需要先插入个知识:Node在编译每个模块时都会创建一个全局变量module,里面维护了当前模块的重要信息,如id、path、exports等等
那么在加载一个模块时会执行上面编译后的函数,并把exports、require、module等参数传进去,我们看这个函数并没有返回什么结果,仅仅是将exports赋值,而module.exports或exports默认值是个空对象{},如果我们导出时使用exports = {},对象的地址引用将会发生变化,而模块的加载最终使用的是module.exports,当然没有任何内容;module.exports = {}形式没有问题,是因为它一直保持着对module的正确引用

模块导入
CommonJS提供require函数来加载一个模块文件:
const theModule = require("./util");require可以加载内置模块、自定义以及第三方库模块,加载是同步的,并且会缓存已经加载过的模块

全局有个唯一对象Module内部会缓存所有加载过的模块,而每个模块也有一个全局变量module,记录着当前模块的一些信息,如:id、path、loaded、filepath等等
ESModule
ESModule是前端目前工程里主流的模块化方案,自NodeJS v12以后也支持了ESModule
- 以
.mjs结尾的文件内部采用es解析
// util.mjs
export function logger(msg) {
console.log(msg);
}
// app.mjs
import { logger } from "./util.mjs";
logger("Hello world!");- 最近的
package.json文件中type:module下的文件都使用es来解析
{
"type": "module"
}然后同级及以下的目录都可以使用es方式写模块了
// util.js
export function logger(msg) {
console.log(msg);
}
// app.js
import { logger } from "./util.js";
logger("hello world");模块加载机制
NodeJS模块加载主要分3个步骤:
- 先判断是不是内置模块
- 若不是内置模块,判断是不是以
/、../或./开头,此类为用户自定义的模块 - 最后就是以第三方模块的形式加载,nodeJS会从当前程序运行的目录
process.cwd()查找node_modules下是否有对应的模块,如果没有则继续往上找对应的node_modules,这样层层向上直到系统根目录
内置模块
和浏览器宿主环境一样,NodeJS也提供了很多内置模块
const builtin = require("node:module")
console.log(builtin.builtinModules)使用node执行上面的代码,会输出所有的内置模块名字:
➜ node builtin.js
[
'assert', 'assert/strict', 'async_hooks', 'buffer', 'child_process', 'cluster', 'console',
'constants', 'crypto', 'dgram', 'diagnostics_channel', 'dns', 'dns/promises', 'domain',
'events', 'fs', 'fs/promises', 'http', 'http2', 'https', 'inspector',
'inspector/promises', 'module', 'net', 'os', 'path', 'path/posix', 'path/win32',
'perf_hooks', 'process', 'punycode', 'querystring', 'readline', 'readline/promises', 'repl',
'stream', 'stream/consumers', 'stream/promises', 'stream/web', 'string_decoder', 'sys', 'timers',
'timers/promises', 'tls', 'trace_events', 'tty', 'url', 'util', 'util/types',
'v8', 'vm', 'wasi', 'worker_threads', 'zlib'
// 等等...
]由于文章篇幅原因,这里捡一些常用的介绍一下
Path
path模块用于处理文件和目录路径。它提供了一组强大的工具来操作和规范路径,使得跨平台开发更加方便和可靠
常用的方法如下:
path.basename(path) // 返回路径的最后一部分,即文件名
path.dirname(path) // 返回路径中目录的部分
path.extname(path) // 返回文件的扩展名
path.join([...path]) // 将多个路径合并成一个
path.resolve([...path]) // 将多个路径合并并解析成绝对路径,也就是一个完成的路径File System
fs模块提供了与文件系统交互的功能。它支持文件的读取、写入、删除、重命名,以及目录操作等功能。fs 模块包含了异步和同步两种 API,便于开发者根据需求选择合适的方式
常用的方法如下:
fs.readFile('example.txt', 'utf-8', (err, data) => {}); // 异步读取文件
fs.readFileSync('example.txt', 'utf-8'); // 同步读取
fs.writeFile('example.txt', 'Hello, Node.js!', (err) => {}); // 异步写入文件
fs.writeFileSync('example.txt', 'Hello, Node.js!'); // 同步写入
fs.appendFile('example.txt', '\nAppend this text!', (err) => {}); // 异步追加内容
fs.appendFileSync('example.txt', '\nAppend this text!'); // 同步追加内容
fs.unlink('example.txt', (err) => {}); // 异步删除
fs.unlinkSync('example.txt'); // 同步删除文件
fs.mkdir('newDir', { recursive: true }, (err) => {}); // 异步创建目录
fs.mkdirSync('newDir', { recursive: true }); // 同步创建目录
fs.readdir('newDir', (err, files) => {}); // 异步读取目录
fs.readdirSync('newDir'); // 同步读取目录
fs.stat('example.txt', (err, stats) => {}); // 获取文件信息
fs.createReadStream('example.txt', 'utf-8'); // 创建可读流
fs.createWriteStream('output.txt'); // 创建可写流
// 流的管道操作等等从NodeJS开始fs模块提供了基于Promise风格的API:
const fs = require("fs/promises");
(async () => {
try {
const data = await fs.readFile("example.txt", "utf-8");
console.log(data);
} catch (err) {
console.error(err);
}
})();Process
process提供了有关当前 Node.js 进程的信息和控制操作。无论你是否显式引入,process 对象始终可用,因为它是全局变量
常用的方法如下:
process.env // 获取变量
process.argv // 获取命令行参数
process.stdin // 标准输入
process.stdout // 标准输出
process.on(eventName) // 监听进程相关事件
process.exit(0|1) // 结束进程:0正常退出,、1非正常
process.cwd() // 当前进程运行目录
process.memoryUsage() // 内存消耗信息Http
http模块用于创建 HTTP 服务器和客户端。它是构建 Web 应用和 API 的基础模块,支持处理 HTTP 请求和响应。大部分前端用户喜爱它的原因可能就是很简单几行代码就搭好了一个web服务
这里写一个简单的例子:
const { createServer, get } = require("nod:http");
const hostname = "127.0.0.1";
const port = 3000;
const server = createServer((req, res) => {
res.statusCode = 200;
res.setHeader("Content-Type", "text/plain");
res.end("Hello World");
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
get(`http://${hostname}:${port}`, (res) => {
res.pipe(process.stdout);
res.on("end", () => {
console.log("接受完毕");
});
});上面req、res对象非常重要,req的类型为IncomingMessage里面包含了很多客户端的一些信息;res为ServerResponse类型用于向客户端发送响应;createServer放回一个Server实例,它继承于Net模块的Server
Net
小贴士
net 模块是 Node.js 提供的底层网络模块,用于创建和管理 TCP 服务器与客户端。它功能强大但较为基础,适合需要灵活控制数据流的场景。对于需要高层次封装的应用(如 Web 开发),可以结合 http 或其他框架使用
从上面我们知道Http.Server继承Net.Server,那么对于HTTP来说net是核心,也要必须搞懂它。在NodeJS中net模块用于创建基于 TCP 或 IPC(进程间通信)的服务器和客户端。它提供了底层的网络通信能力,是构建实时应用、聊天系统、或自定义协议服务器的基础
创建TCP服务器:
const net = require("node:net");
// 创建服务器
const server = net.createServer((socket) => {
console.log("New client connected");
// 监听客户端数据
socket.on("data", (data) => {
console.log(`Received: ${data.toString()}`);
socket.write(`Echo: ${data}`); // 回显数据
});
// 监听客户端断开连接
socket.on("end", () => {
console.log("Client disconnected");
});
});
// 监听端口
server.listen(3000, () => {
console.log("TCP Server running on port 3000");
});创建TCP客户端:
const net = require('node:net');
// 创建客户端并连接到服务器
const client = net.createConnection({ port: 3000 }, () => {
console.log('Connected to server');
client.write('Hello, server!');
});
// 监听数据
client.on('data', (data) => {
console.log(`Received: ${data.toString()}`);
client.end(); // 结束连接
});
// 监听连接结束
client.on('end', () => {
console.log('Disconnected from server');
});
一些常用的方法属性:
net.createServer // 创建TCP服务
net.connect/net.createConnection // 创建TCP客户端
server.listen // 监听端口
sockot.write // 发送数据
socket.end // 结束链接
socket.pipe // 流传输
socket.on/server.on // 事件监听Zlib
zlib模块提供数据压缩与解压缩的功能,支持多种压缩格式(如 gzip 和 deflate)。它基于 zlib 压缩库,实现了高效的流式数据压缩和解压操作,广泛应用于文件压缩、HTTP 请求或响应的内容压缩等场景
基本的压缩解压案例:
const fs = require("node:fs");
const zlib = require("node:zlib");
(async () => {
// 压缩文件
const input = fs.createReadStream("./input.txt");
const output = fs.createWriteStream("./input.txt.gz");
input.pipe(zlib.createGzip()).pipe(output);
await new Promise((resolve) => setTimeout(resolve, 1000));
// 解压文件
const compressed = fs.createReadStream("./input.txt.gz");
const decompressed = fs.createWriteStream("./output.txt");
compressed.pipe(zlib.createGunzip()).pipe(decompressed);
})();结合http请求进行zlib压缩:
const { createServer } = require("node:http");
const fs = require("node:fs");
const zlib = require("node:zlib");
const filePath = "./input.txt";
createServer((req, res) => {
const gzip = zlib.createGzip();
res.setHeader("Content-Encoding", "gzip");
res.setHeader("Content-Type", "text/plain; charset=utf-8");
fs.createReadStream(filePath).pipe(gzip).pipe(res);
}).listen(3000, () => console.log("server start on 3000 port."));访问当前服务器:

全局变量
NodeJS提供了一些全局可以访问的变量,它们在所有模块中都可以使用,无需 require 或显式声明
global:是 Node.js 中的全局对象(类似于浏览器中的 window);所有全局变量都可以通过 global 访问__dirname:表示当前模块文件所在目录的绝对路径__filename:表示当前模块文件的绝对路径process:当前 Node.js 进程的信息和控制,包含环境变量、命令行参数、标准输入输出、事件等require:用于加载模块Buffer:处理二进制数据module/exports:表示当前模块的对象,导出模块内容
npm包管理器
除了在NodeJS中使用内置模块和自定义模块外,还可以安装第三方库使用,而使用第三方软件包通常都需要借助包管理器,npm就是一个标准的NodeJS软件包管理器,这里简单介绍如何使用
# 下载指定包
npm install packageName
# 指定版本
npm install packageName
# 安装所有依赖
npm install命令比较多就不一一列举了,建议读者查看文档
由于npm自身的一些问题,陆续出现Yarn、Pnpm、Bun等后起之秀
部署应用
虽然使用node filename就可以运行应用程序,但可能一些运行时错误、内存泄漏等问题会造成应用崩溃,因此使用一个专业的工具最为合适
目前常见的部署工具为 pm2,它是一个守护程序进程管理器,它将帮助您管理和保持应用程序在线。开始使用PM2很简单,可作为简单而直观的CLI提供,可通过npm安装
# 安装到全局
npm install pm2 -g
# 简单部署脚本
pms start app.js --name test_deploy部署后的应用可以通过下面一些命令管理:
# 重启应用,平滑重启,不会造成中断
pm2 reload app_name
# 重启应用(完全停止后重启)
pm2 restart app_name
# 停止应用
pm2 stop app_name
# 删除应用
pm2 delete app_name除此之外你还可以查看应用的运行情况:
# 列出所有的应用
pm2 ls
# 所有日志
pm2 logs [app_name] [-f]不过只使用上面的这种方式部署感觉和直接使用node运行应用的方式大差不差,虽然可以通过一些参数对内存、重启等健康检查,但完全是个黑箱操作,而生产环境通常都会使用配置文件来部署
执行pm2 init 或 pm2 ecosystem 生成 配置文件ecosystem.config.js:
module.exports = {
apps: [
{
name: "app1",
script: "./app.js",
env_production: {
NODE_ENV: "production",
},
env_development: {
NODE_ENV: "development",
},
},
],
};然后在终端执行:
pm2 start ecosystem.config.js --env production该配置文件还支持很多有用的属性
| Field | Type | Example | Description |
|---|---|---|---|
| name | (string) | “my-api” | 应用程序别名 |
| script | (string) | ”./api/app.js” | 应用程序入口 |
| cwd | (string) | “/var/www/” | 应用程序被执行的根目录 |
| args | (string) | “-a 13 -b 12” | 所有的参数 |
| interpreter | (string) | “/usr/bin/python” | 可执行的解释器路径,默认为node |
| interpreter_args | (string) | ”–harmony” | 传给解释器的参数 |
| node_args | (string) | 同上 | |
| instances | number | -1 | 程序启动的实例数目 |
| exec_mode | string | “cluster” | 启动程序的模式cluster/fork,默认fork |
| watch | boolean or [] | true | 启用监视、重启特性,如果文件改变应用将会平滑重启 |
| ignore_watch | list | ['[/\]./', 'node_modules'] | 忽略监视的列表支持正则 |
| max_memory_restart | string | “150M” | 应用内存最大多少重启 |
| env | object | {“NODE_ENV”: “development”, “ID”: “42”} | 程序启动时自动注入 |
| env_ | object | {“NODE_ENV”: “production”, “ID”: “89”} | 运行时根据--env xxx来匹配对应的配置然后注入 |
还有很多有用配置建议阅读官方文档
错误捕获
NodeJS中有2类重要的全局错误捕获事件unhandledRejection、uncaughtException:
- unhandledRejection:用来捕获异步程序没有捕获的错误,如promsie、async运行中产生的错误
- uncaughtException:用来捕获同步代码中没有被捕获的错误
来看下面一段简单的演示:
// 抛出异步错误
Promise.reject('异步错误');
process.on('unhandledRejection', (reason, p) => {
console.log('Unhandled Rejection at: Promise', p, 'reason:', reason);
// 抛出同步错误
throw new Error('同步错误');
});
process.on('uncaughtException', (error, origin) => {
// origin: "uncaughtException" | "unhandledRejection";
console.log('uncaughtException', error);
})除此之外很多模块都有对应的错误处理方式,如监听流的错误stream.on(error)等等,开发者使用时可以翻阅文档结合场景使用
事件循环
小贴士
NodeJS是一个单线程服务,之所以它有很好的并发性是由于背后的EventLoop,主线程通过事件循环机制提供线程池来执行其他任务
讲到事件循环相信很多读者都看我的往期文章「EventLoop事件循环机制」,Node和浏览器都是基于v8引擎,浏览器中的异步方法node中也会有,除此之外还包括:
- 文件I/O
- process.nextTick
- setImmediate
- 监听关闭事件
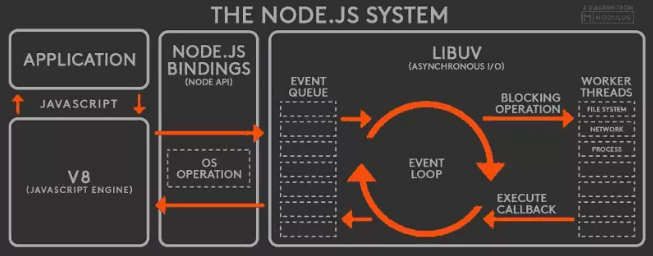
Node中的事件循环机制是基于Libuv(Asynchronous I/O)引擎实现的,v8引擎会分析对应的js代码然后调用node的api,而node又被libuv驱动执行对应的任务,并把任务放入到对应的任务队列等待主线程的调度,因此node的EventLoop是libuv里实现的,看下node原理图:
执行阶段
node事件循环机制中和浏览器的不太一样,在node中一般不说微任务和宏任务,通常分为不同的执行阶段,在这些不同的执行阶段都会有对应任务队列,各自执行任务队列里的任务;node就是这样不断循环这些不同的执行阶段调度任务的执行顺序,其EventLoop包括以下执行阶段:
小贴士
如果某个阶段的任务有很多很多,它并不会无限的执行下去,每个阶段会有一个任务执行数量限制
timers:执行定时器任务队列回调:setTimeout、setInterval...pending callback:执行除了定时器、setImmediate以外的大部分回调,如操作系统TCP连接回调、IO回调等等。idle、prepare:内部调度不用关心poll:等待新的请求连接或I/O事件。node一开始进入这个阶段,如果当前阶段的任务队列执行空,先看有没有setImmediate回调,如果有进入check执行setImmediate回调,或等待新的I/O请求连接,同时也会检测timer是否有到期,若有会直接进入timer阶段执行回调,受代码执行环境的影响check:执行setImmediate回调close:执行socket等关闭操作回调
以下是来自官网事件循环示意流程⬇️
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘以上每个阶段的任务执行完在进入下一个阶段前会先清空当前阶段的微任务队列,而老版本的node则会先把当前阶段的代码回调执行完后才会执行微任务队列,如下代码:
setTimeout(() => {
console.log("setTimeout1");
Promise.resolve().then(() => console.log("promise1"));
});
setTimeout(() => {
console.log("setTimeout2");
Promise.resolve().then(() => console.log("promise2"));
});- 使用node版本(9.11.2),打印顺序:
setTimeout1=>setTimeout2=>promise1=>promise2,node会先将timer阶段的回调执行完后,才会执行当前阶段微任务队列中的所有微任务 - 浏览器打印顺序:
setTimeout1=>promise1=>setTimeout2=>promise2 - 使用高版本node打印顺序和浏览器一致
setTimeout和setImmediate
通常情况下我们都会使用setTimeout执行延时任务,在node中也提供了setImmediate来执行异步任务表示立即执行,前面讲到它在check阶段执行;若将setTimeout的时间设置为0是不是和前者有同样的效果:
setTimeout(() => console.log("setTimeout"));
setImmediate(() => console.log("setImmediate"));多次执行以上代码会发现打印顺序并不固定,这是为什么呢?
以上代码就两个异步任务,前面讲了node刚开始会进入poll阶段,如果当前阶段没有任何任务要执行时,就会看看有无setImmediate回调,如果有的话进入check阶段执行回调,但是同时也会监听setTimeout的回调,如果到期也会立马进入timer阶段去执行定时器的回调,两者优先级不是固定的,这就是为什么打印顺序并不是一致的原因
现在将上面的代码稍作修改,让其在IO回调里执行:
const fs = require("fs")
fs.readFile(__dirname + "/inherit.js", 'utf8', (err, data) => {
setTimeout(() => console.log("setTimout"));
setImmediate(() => console.log("setImmediate"));
})以上的打印顺序永远是setImmediate => setTimeout,为什么呢?因为上面代码是在IO回调里执行的。回到事件循环的执行阶段中,I/O回调会在pending callback阶段执行,按照事件循环机制check阶段会在timer阶段前执行,所以为什么打印顺序不会变
process.nextTick
process.nextTick也是立即执行的意思,但它和setImmediate不一样的是,其不是阶段性的任务。process.nextTick在每个阶段同步任务执行完后都会执行,并且优先于微任务(promise)执行:
setTimeout(() => {
Promise.resolve().then(() => console.log("promise"));
process.nextTick(() => console.log("nextTick"));
});
setImmediate(()=> console.log('setImmediate'));打印顺序有2种:如果你不明白为啥有2种❓再看看上个章节Immediate
nextTick => promise => setImmediate
setImmediate => nextTick => promise上面执行结果promise和nextTick打印永远在一起,并且nextTick印永远会在promise之前打印,而setImmediate只会在check阶段打印
按照执行时机,process.nextTick更适合于立即执行某个任务
事件发射器
与浏览器的事件监听系统(鼠标、键盘等等)类似,NodeJS也提供了事件监听系统 Events,其实核心就是一个发布订阅架构,比较简单:
const EventEmitter = require('node:events');
const emitter = new EventEmitter();
const logger = msg => console.log(msg);
emitter.on('logger', logger);
emitter.emit('logger', 'Hi, EventEmitter!');
emitter.off('logger', logger);
emitter.emit('logger', ''); // 已解绑,没任何反应生态系统
Nodejs它不仅广泛用于构建服务器端应用,还拥有一个丰富的生态系统,涵盖了框架、工具、库和社区资源。Node.js 生态系统是推动现代 JavaScript 开发的核心力量 (🐶JS是世界上最好的语言)
- 包管理器:npm、yarn、pnpm
- web框架:express、koa、nest
- 实时通信框架:socket.io、ws
- 静态服务器:serve、http-server
- 数据库驱动:MySQL、mongodb、postgreSQL、redis
- orm:typeorm、sequelize、mongoose
- 构建工具:webpack、vite、parcel、rollup、babel、esbuild
- 测试工具:mocha、jest、cypress
- 性能监控:clinic、newrelic
- 日志工具:winston、pino
NodeJS真的无所不能‼️
参考文档
感谢支持



