NodeJS性能优化手册
Node.js 是一个高效的 JavaScript 运行时环境,以其非阻塞的 I/O 模型和事件驱动架构广受欢迎。它非常适合处理大量并发连接,尤其在构建 I/O 密集型应用时具有无与伦比的性能优势。然而,随着应用规模的扩大和复杂度的增加,性能问题可能会逐渐显现
为了保持系统的高效和可扩展性,Node.js 的性能优化变得至关重要。本文将详细探讨如何优化 Node.js 应用的性能
小贴士
文章中涉及到的代码示例你都可以从 这里查看 ,若对你有用还望点赞支持
理解Nodejs性能瓶颈
Node.js 的核心优势在于其异步 I/O 模型,这使得它能够在单线程下处理高并发。Node.js 通过 事件循环机制(Event Loop)来管理异步操作。简单来说,Node.js 在进行 I/O 操作(如文件读取、数据库查询等)时,不会阻塞当前线程,而是将这些操作交给底层操作系统处理。一旦操作完成,Node.js 会通过事件通知来触发回调函数
--------------------------------
| Event Loop |
--------------------------------
| | | |
Poll Check Execute Timers虽然通过事件驱动模型避免了传统阻塞式 I/O 的问题,但它仍然是 单线程 的,这意味着它在执行 CPU 密集型任务时会遇到瓶颈。当 Node.js 处理大量计算密集型操作(如图像处理、大数据计算)时,主线程会被阻塞,从而导致整个应用的性能下降
接下来将从分析工具到编码优化的流程带读者深刻认识性能优化的整个流程
性能分析工具
在开始优化之前,首先需要了解应用的性能瓶颈在哪里。Node.js 提供了一些内置工具和第三方工具来帮助我们进行性能分析
memoryUsage
内置的process模块提供了 memoryUsage 方法来查看当前Nodejs进程的内存使用情况,在程序运行时直接打印它的执行结果 console.log(process.memoryUsage()) :
{
rss: 49053696,
heapTotal: 8159232,
heapUsed: 6468480,
external: 2317585,
arrayBuffers: 16631
}它返回一个对象,包含以下几个关键字段,分别表示内存使用的不同方面:
- rss:进程占用的物理内存总量
- heapTotal:V8 引擎分配的堆内存总量
- heapUsed:V8 引擎已使用的堆内存量
- external:V8 引擎管理的、绑定到 JavaScript 对象的 C++ 对象的内存使用量
- arrayBuffers:分配给 ArrayBuffer 和 SharedArrayBuffer 的内存
使用此方式可以简单的了解到内存的情况,适用于简单测试的小场景
Node Profiler
Node Profiler 是 Node.js 中的一个性能分析工具,它可以通过 --prof 标志启用。这个标志会生成一个 V8 分析日志文件
- 使用
--prof标志运行您的应用程序:
node --prof server.js- 运行结束后,会生成一个名为
isolate-0xnnnnnnnnnnnn-v8.log的日志文件 - 使用
--prof-process标志处理日志文件,生成可读的报告:
node --prof-process isolate-0x110008000-16791-v8.log > processed.txt打开 processed.txt 文件,查看分析结果。报告会显示每个函数的调用次数、执行时间等信息:
Statistical profiling result from isolate-0x110008000-16791-v8.log, (194 ticks, 187 unaccounted, 0 excluded).
[Shared libraries]:
ticks total nonlib name
[JavaScript]:
ticks total nonlib name
1 0.5% 0.5% RegExp: %2F|%5C
1 0.5% 0.5% JS: ~resolve node:path:1095:10
1 0.5% 0.5% JS: ~depd /Users/ihengshuai/Desktop/temp/html-quick-test/node_modules/depd/index.js:103:15
1 0.5% 0.5% Builtin: StringIndexOf
1 0.5% 0.5% Builtin: LoadIC_NoFeedback
1 0.5% 0.5% Builtin: BaselineOutOfLinePrologue
1 0.5% 0.5% Builtin: ArrayPrototypePush
[C++]:
ticks total nonlib name
[Summary]:
ticks total nonlib name
7 3.6% 3.6% JavaScript
0 0.0% 0.0% C++
3 1.5% 1.5% GC
0 0.0% Shared libraries
187 96.4% Unaccounted
### 省略...上面生成文件内容跟对来说友好些,但是并不是很直观,接下来借助可视化工具查看
Chrome DevTools Performance
Chrome Devtools的Performance面板前端同学应该都很熟悉,打开它可以你可以选择实时记录性能也可以导出记录文件
上传记录文件:点击顶部上传按钮

然后加载刚刚生成的 profile 文件就可以可视化查看相关数据了
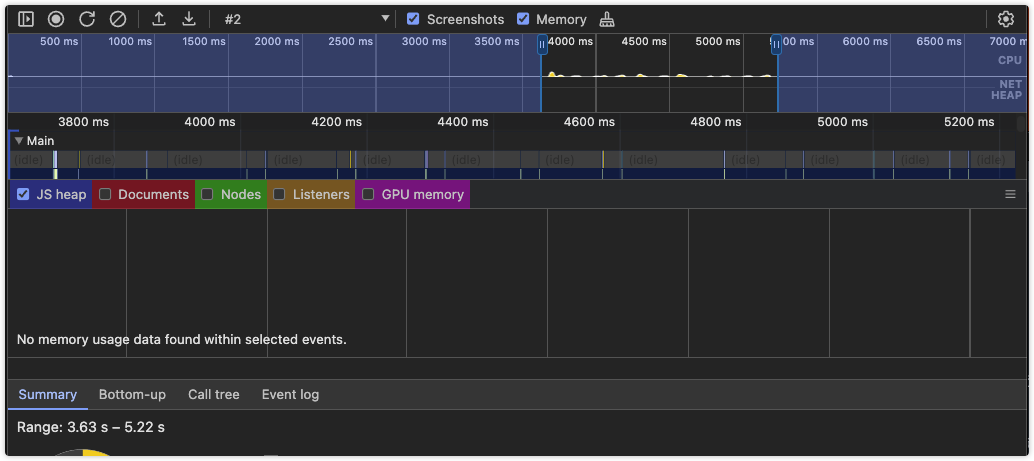
直接记录:有时候可以直接在Performance中记录Node的运行情况,此种方式需要使用node调试模式,然后使用Chrome来作为调试UI,这样就可以记录了

node启动debug模式后打开Chrome 输入chrome://inspect/#devices,找到Remote Target为node的目标文件然后点击打开新的窗口;然后打开Performance点击左上角记录就可以了
小贴士
这些都是和调试技能相关的,如果你对调试或者抓包还不是很熟悉,推荐阅读我的往期相关文章 VSCode调试技巧
Chrome DevTools内存分析
Chrome DevTools也是支持内存大小使用情况分析的,点击 Memory 栏后可以点击上传内存记录文件就可以查看对应的使用情况了
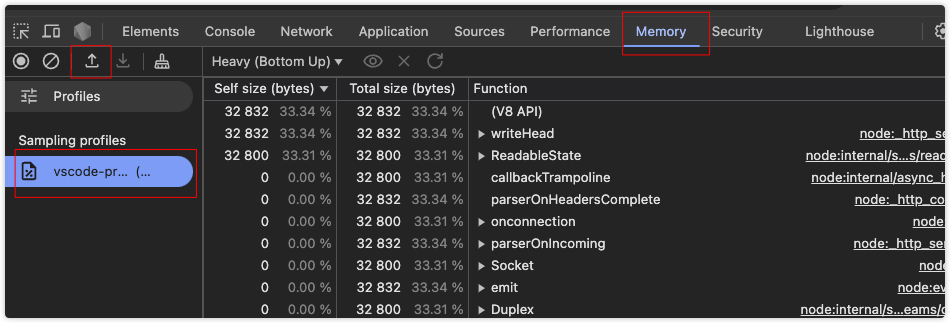
VSCode分析CPU及内存
上面我们使用node --prof生成对应的日志文件后,然后使用Chrome来加载对应的性能日志文件,让简单的文本数据可视化变得更容易分析。而使用vscode调试可以继承前面所有步骤,让性能分析变得更简单
首先就是我们使用vscode以调试模式启动node(不懂调试的查看往期文章),然后点击左侧堆栈里面的 Take Performance Profiler 按钮,就会弹出三种性能分析选项,选择一个想要测试的就行

这里选择了Heap Profile,然后debuggerUI最后面红点表示正在记录

现在去发送请求啥的去测试服务器,最后点击红色按钮结束后就会生成对应的日志文件

是不是这样子更方便点,感兴趣的可以试试其他几种类型监测
但是这样子还是没有达到可视化,体验好像还不是很好。幸运的是vscode提供了可用的插件,接着往下看
实时火焰图
火焰图 Flame插件 可以将一些性能记录文件进行可视化展示,方便更友好的分析数据,这方面就类似上文提到的Chrome DevTools一样
下载好这个插件后,在vscode中打开刚刚生成的日志文件,这时候就可以看到,最后面有一个火焰的图形

点击它后就会以可视化的方式呈现出来
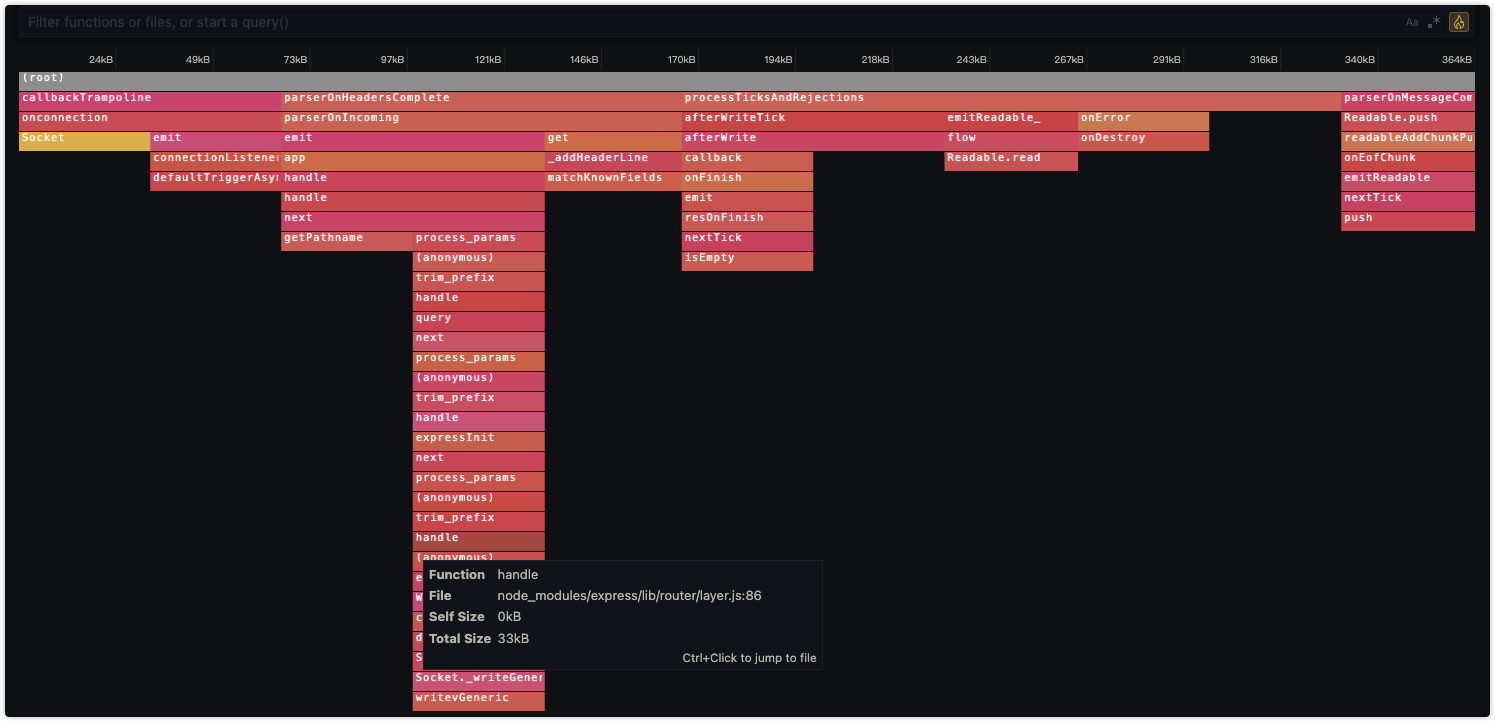
对于 CPU 情况,水平轴是时间线,允许您查看程序在每个时间点正在做什么。对于堆内存情况,水平轴是程序分配的总内存
滚动鼠标滚轮可以放大缩小到某个时间点的数据情况,基本和Chrome DevTools一样
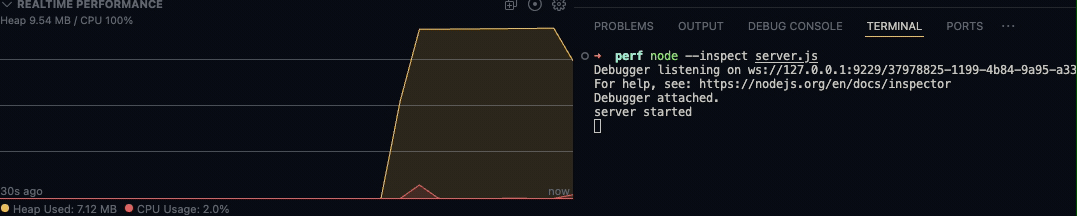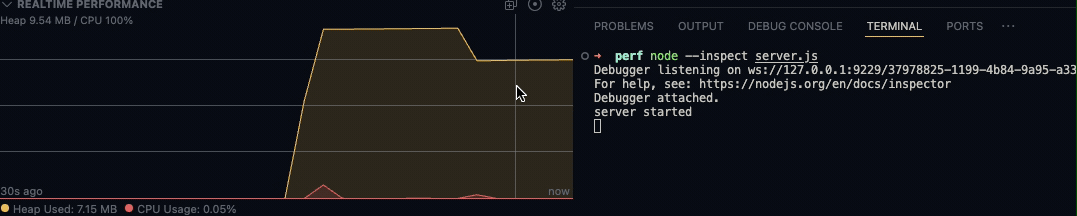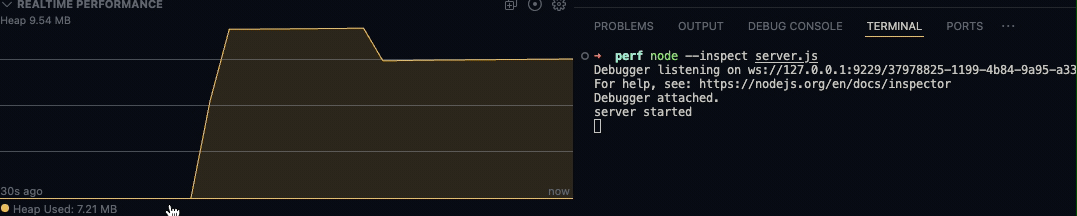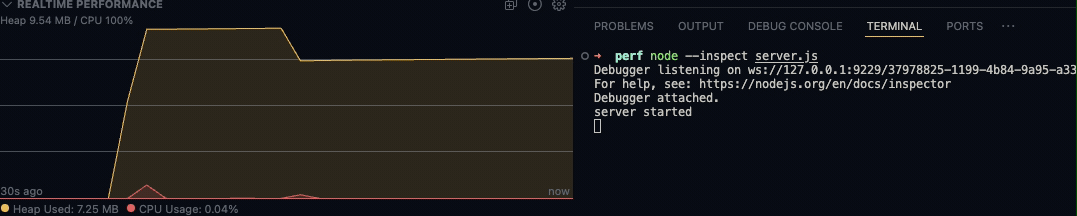
而除了以可视化的方式查看指定的日志文件外,Flame插件也支持实时查看相关数据,此方式需要以vscode调试模式运行程序。然后在Debugger最下方一栏中REALTIME PERFORMANCE呈现出来
clinic
clinic 是一个专门为 Node.js 应用程序设计的性能分析工具套件,旨在帮助开发者快速诊断和优化性能问题。它由 NearForm 开发,提供了一系列工具来分析和可视化 Node.js 应用程序的性能瓶颈
Clinic.js 的核心工具包括 Doctor、Flame 和 Bubbleprof,每个工具都有其独特的用途和分析方式
- 安装
npm install clinic -g- 使用Clinic Doctor运行nodejs
clinic doctor -- node server.js运行起来后开始压测服务器,最后Ctrl+C结束程序后,clinic会自动生成报告文件,并启动在浏览器打开
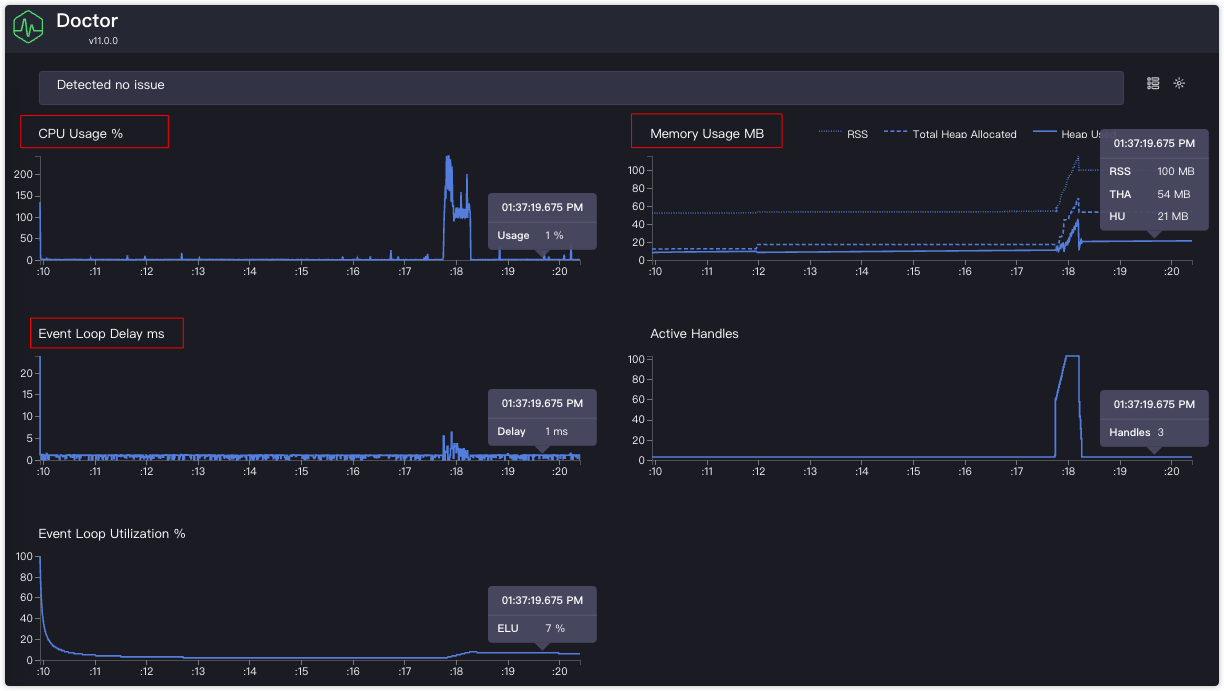
报告中会包含 CPU、Memory等相关维度的指标数据,并以统计图的方式呈现出,非常明确
除此之外有明显的性能问题,顶部还会显示哪些地方需要改进

- clinic也支持火焰图,可以使用Cliic Flame运行nodejs
clinic flame -- node server.js运行结束后自动火焰图报告
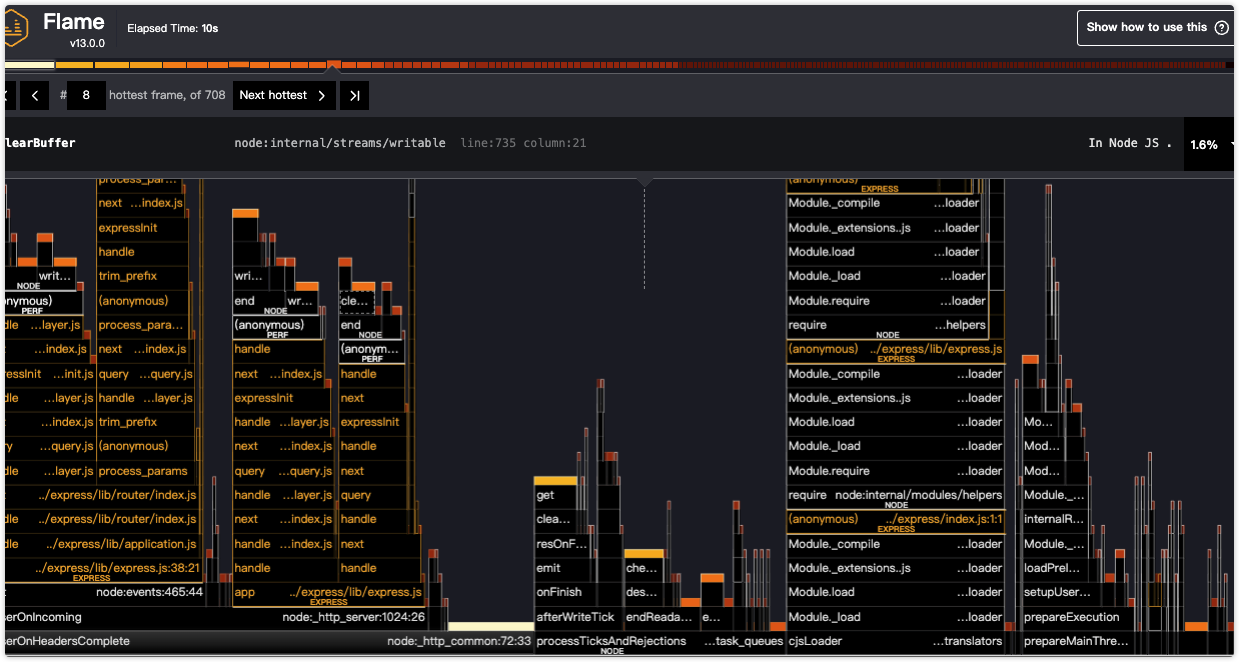
Node压测工具
通常在开发环境简单请求访问测试程序性能问题很难达到性能瓶颈,因此需要借助压测工具。通过压测工具,开发者可以评估系统在高负载下的表现,识别性能瓶颈(如响应时间延迟、内存泄漏、CPU 过载等),并验证系统的承载能力
常用的压测工具有ab、autocannon、webbench等等,本文介绍前两款常用工具
ab
ab(Apache Benchmark) 是一个简单且广泛使用的压测工具,由 Apache 软件基金会开发。它主要用于对 HTTP 服务器进行性能测试,能够模拟大量并发请求
安装
# centos
yum install httpd-tools
# macos
brew install apache-httpd
# windows 直接下载apache服务器简单尝试:
ab -n 10000 -c 120 http://localhost:3000/上面执行完后会简单在终端显示对应的统计数据,主要包含以下内容
请求统计:- Complete requests:完成的请求数
- Failed requests:失败的请求数
时间统计:- Time taken for tests:总测试时间
- Requests per second:每秒处理的请求数(吞吐量)
Time per request:每个请求的平均处理时间连接时间:- Connect:建立连接的时间
- Processing:服务器处理请求的时间
- Waiting:等待服务器响应的时间
百分比分布:50%、90%、95% 等百分位的请求处理时间

以下列出 ab 工具的常用命令选项及其说明:
| 选项 | 说明 | 示例 |
|---|---|---|
-n | 执行的总请求数 | -n 1000 表示发起 1000 次 HTTP 请求 |
-c | 并发请求数 | -c 100 表示同时发起 100 个并发请求 |
-t | 压测的最大持续时间(秒) | -t 30 表示测试最多持续 30 秒 |
-p | 包含 POST 数据的文件路径 | -p post.txt 将 post.txt 的数据作为请求体 |
-u | 包含 PUT 数据的文件路径 | -u put.txt 将 put.txt 的数据用于 PUT 请求 |
-T | 指定 Content-Type(MIME 类型) | -T application/json 指定 JSON 类型 |
-H | 自定义 HTTP 头信息 | -H "Authorization: Bearer token" |
-A | 添加 HTTP 基本认证(用户名:密码) | -A admin:password |
autocannon
Autocannon 由nodejs开发可以在命令行使用,同时也支持通过 JavaScript API 进行编程式调用,非常适合 Node.js 开发者使用
安装:
npm i autocannon -g命令格式:
autocannon [选项] <URL>简单尝试:
autocannon http://localhost:3000 -c 100 -a 3000执行结束后以表格的形式展示统计结果
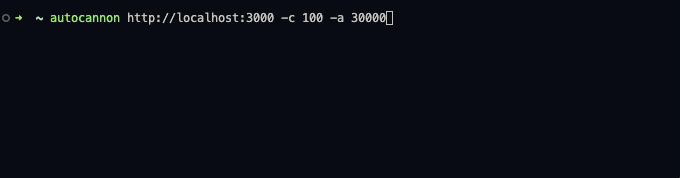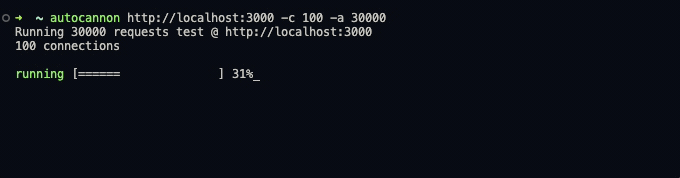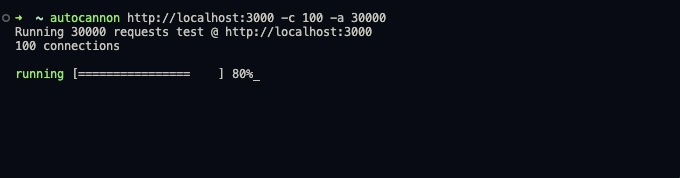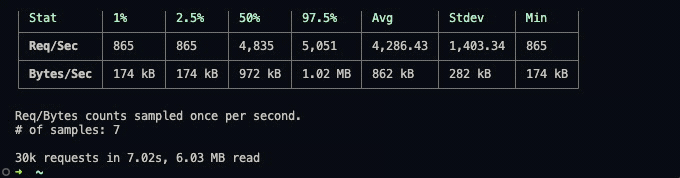
数据主要包含2个表格,分别统计 每秒吞吐量 和 延迟
同时它还支持在程序中以sdk形式调用:
const autocannon = require('autocannon')
autocannon({
url: 'http://localhost:3000',
connections: 10, //default
pipelining: 1, // default
duration: 10 // default
}, console.log)
// async/await
async function foo () {
const result = await autocannon({
url: 'http://localhost:3000',
connections: 10, //default
pipelining: 1, // default
duration: 10 // default
})
console.log(result)
}使用方式比较简单读者可自行翻阅文档
EventLoop优化
Node.js 的 Event Loop 是其单线程非阻塞架构的核心,通过事件驱动模型高效处理并发任务。然而由于其单线程特性,长时间运行同步任务或者CPU密集性任务,就会造成事件循环阻塞,那么程序很可能就会崩溃
在编写nodejs应用时尽量不要写太多的同步任务,可以使用它的异步版本,下面举几个🌰
const http = require("http");
http
.createServer((req, res) => {
if (req.url === "/compute") {
// 模拟阻塞任务
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
}
res.end(`Sum is ${sum}`);
} else {
res.end("OK");
}
})
.listen(3000, () => console.log("Server running on port 3000"));上面在请求时执行了大量的同步任务,会阻塞后面的任务调度,可以借助setImmediate 将任务推到事件队列的下一轮
let i = 0;
const processChunk = () => {
while (i < 1e8 && i % 1e6 !== 0) {
i++;
}
if (i < 1e8) {
setImmediate(processChunk); // 将任务推到事件队列的下一轮
} else {
// 响应...
res.end()
}
};
processChunk();IO优化
I/O(输入/输出)操作往往是性能瓶颈的主要来源之一。无论是文件读写、数据库查询,还是网络请求,I/O 操作通常涉及与外部资源的交互,而这些交互的延迟和效率直接影响着应用程序的整体性能
Stream流
使用流(Stream)代替一次性读取
const fs = require('fs');
const readStream = fs.createReadStream('file.iso');
readStream.on('data', (chunk) => {
console.log(chunk.toString());
});连接池
连接池可以显著提升应用程序的性能,尤其是在处理高并发请求或频繁访问外部资源(如数据库、API 等)时。连接池通过复用和管理连接资源,减少了创建和销毁连接的开销,从而提高了系统的效率和响应速度
import mysql from 'mysql2/promise';
const pool = mysql.createPool({
host: 'localhost',
user: 'root',
database: 'test',
waitForConnections: true,
connectionLimit: 10,
maxIdle: 10, // max idle connections, the default value is the same as `connectionLimit`
idleTimeout: 60000, // idle connections timeout, in milliseconds, the default value 60000
queueLimit: 0,
enableKeepAlive: true,
keepAliveInitialDelay: 0,
});连接池的核心思想是预先创建一定数量的连接,并将这些连接保存在一个“池”中。当应用程序需要访问外部资源时,从池中获取一个空闲连接,使用完毕后将连接归还到池中,而不是立即销毁。这样可以避免频繁创建和销毁连接的开销
Buffer
Buffer 是用于直接操作二进制数据的核心模块。它提供了一种高效的方式来处理原始内存中的数据,特别适用于处理文件、网络流、加密等 I/O 密集型操作
在网络通信中,数据通常以二进制形式传输
const http = require("http");
http.get("http://example.com", (res) => {
const chunks = [];
res.on("data", (chunk) => {
chunks.push(chunk); // chunk 是一个 Buffer
});
res.on("end", () => {
const data = Buffer.concat(chunks);
console.log(data.toString());
});
});并发优化
高并发处理能力是衡量系统性能的重要指标之一,Node.js 凭借其非阻塞 I/O 和事件驱动架构,天生具备处理高并发请求的优势,但这并不意味着我们可以忽视并发优化的必要性
虽然单线程事件循环模型虽然高效,但在 CPU 密集型任务或极端高并发场景下,仍然可能遇到性能瓶颈。通过合理的并发优化策略,如集群化部署、任务分片、异步编程优化以及资源池化管理,我们可以显著提升系统的吞吐量和响应速度
多线程/多进程
EventLoop大多数都是服务于IO操作的,这些操作可以通过异步回调的方式执行计算结果,但对于JS的运行往往都在那个单线程上,如果一个业务逻辑涉及到CPU密集的同步计算,就会阻塞后面的请求,那并发性就更不用提了
const express = require("express");
const app = express();
function runCompute() {
for (let i = 0; i < 10e9; i++) { /* do nothing */ }
}
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
runCompute();
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});程序表达的意思很简单,就是在请求服务器时用runCompute来模拟一段高密集的计算,然后看看请求的打印时间。启动服务器后,同时发起2个请求,我们看看他的日志情况
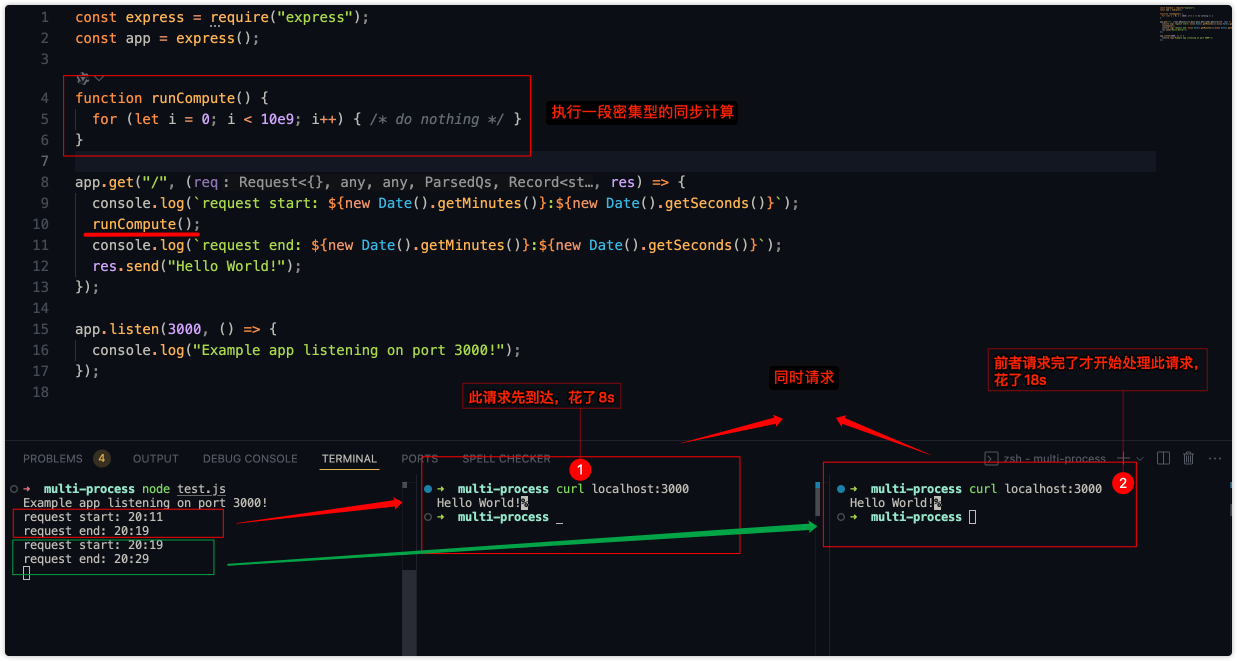
虽然2个请求是同时发出的,但从打印的时间很明显可以看出服务器只能同时处理一个请求,当前面的请求处理完后才开始处理后面的请求。到这里应该知道明白点为什么会这样了吧,虽然NodeJS有很出色的并发性能但那都是基于异步、IO操作,当遇到同步密集型的计算就招架不住了😱
使用多进程形式稍微改造下上面的代码:
// cpu-compute.js
function runCompute() {
for (let i = 0; i < 10e9; i++) { /* do nothing */ }
}
process.on('message', () => {
runCompute();
process.send('done');
process.exit(0);
});
// cpu-compute-main.js
const express = require("express");
const app = express();
const child_process = require("node:child_process");
app.get("/", (req, res) => {
console.log(`request start: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
const child = child_process.fork("./cpu-compute.js");
child.send("start");
child.on("message", () => {
console.log(`request end: ${new Date().getMinutes()}:${new Date().getSeconds()}`);
res.send("Hello World!");
});
});
app.listen(3000, () => {
console.log("Example app listening on port 3000!");
});再看看执行情况,很明显程序能够同时处理请求了,请求都之花了9s,并且没有造成阻塞;这就是使用多核CPU计算的优势

集群
Node.js 是单线程的运行时,默认通过事件循环处理非阻塞 I/O,这种模型虽然高效,但会受限于单线程性能,尤其在高并发或多核 CPU 的环境下无法充分利用系统资源。为了解决这一问题,Node.js 提供了 集群(Cluster) 模块,用于实现多进程架构,在多核环境中提升性能
const cluster = require("node:cluster");
const http = require("node:http");
const os = require("node:os");
if (cluster.isMaster) {
// 主进程逻辑
const numCPUs = os.cpus().length;
console.log(`主进程 ${process.pid} 正在运行`);
// 创建与 CPU 核心数量相等的工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听工作进程退出事件
cluster.on("exit", (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
// 可选择性地重启工作进程
cluster.fork();
});
} else {
// 工作进程逻辑
http
.createServer((req, res) => {
res.writeHead(200);
res.end(`你好!工作进程:${process.pid}`);
})
.listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}运行程序后多次请求服务,会发现处理请求的进程会一直发生变化,而这背后正是cluster的负载均衡算法支配的

cluster还有很多重要的属性和方法,都比较容易懂读者可自行查阅文档。在这种集群模式下编写代码区别不大,最多就是通过来判断主进程和子进程进行区分
缓存
缓存是指将频繁访问的数据存储在快速访问的存储介质(如内存)中,以便后续请求可以直接从缓存中获取数据,而不需要重新计算或查询原始数据源
缓存 是优化应用程序性能的重要手段之一,通过缓存,可以减少重复计算、降低数据库或外部服务的负载,从而显著提升系统的响应速度和吞吐量
内存缓存
内存缓存是将数据存储在应用程序的内存中,适合存储小规模、高频访问的数据。Node.js 中可以使用 node-cache 内存缓存工具
const NodeCache = require("node-cache");
const cache = new NodeCache({ stdTTL: 100, checkperiod: 120 }); // 设置缓存过期时间和检查周期
// 设置缓存
cache.set("key", "value", 10); // 10 秒后过期
// 获取缓存
const value = cache.get("key");
if (value) {
console.log("Cache hit:", value);
} else {
console.log("Cache miss");
}分布式缓存
分布式缓存是将缓存数据存储在多个节点上,适合大规模、高并发的场景。nodejs中可以使用 redis 管理分布式缓存
const redis = require("redis");
const client = redis.createClient(); // 创建 Redis 客户端
// 设置缓存
client.set("key", "value", "EX", 10, (err) => {
// 10 秒后过期
if (err) throw err;
});
// 获取缓存
client.get("key", (err, value) => {
if (err) throw err;
if (value) {
console.log("Cache hit:", value);
} else {
console.log("Cache miss");
}
});动静分离/HTTP缓存
动静分离是指将 Web 应用中的静态资源(如 HTML、CSS、JavaScript、图片等)和动态内容(如 API 响应、数据库查询结果等)分开处理。静态资源通常不会频繁变化,而动态内容则根据用户请求实时生成
将静态资源(如 CSS、JS、图片)托管到专门的静态资源服务器或 CDN(内容分发网络)上或使用 Nginx 或 Apache 作为静态资源服务器
通过 HTTP 头控制客户端(如浏览器)或代理服务器缓存资源的一种机制。它可以减少重复请求,加速资源加载,降低服务器负载
这里就不过多介绍了,应该很多读者都会接触到,如果你对此有疑惑可以查看我的往期文章 Nginx使用手册
安全
Node.js 的安全性能优化需要从多个方面入手,包括身份验证、防止常见攻击、日志监控、配置安全、文件上传安全、数据库安全、性能优化和定期安全审计等等
比如恶意的DDoS攻击通过大量恶意请求耗尽服务器资源,限流是防止 DDoS 攻击的基础措施,通过限制每个客户端或 IP 的请求频率,防止恶意请求耗尽服务器资源。在node中可以使用 express-rate-limit :
const rateLimit = require("express-rate-limit");
const limiter = rateLimit({
windowMs: 15 * 60 * 1000, // 15 分钟
max: 100, // 每个 IP 最多 100 次请求
});
app.use(limiter);还有其他通常见的HTTP攻击,往期文章都做了解释和如何规避,读者可以查看 HTTP协议及安全防范
而对于一些文件上传、数据库等等则需要更多的手段,由于篇幅原因这里就多做介绍了,相信很多读者都有了解过
总结
Node.js 性能优化是一个多层次、多维度的过程,旨在通过优化代码、架构和资源配置,提升应用程序的响应速度、吞吐量和资源利用率。从异步编程与事件循环的合理使用,到缓存机制、连接池和数据库查询的优化,再到动静分离、CDN 加速和集群化部署,每一步都至关重要。同时,安全性能的保障和监控工具的引入,确保了系统在高性能运行下的稳定性和可靠性
性能优化并非一劳永逸,而是一个需要持续分析、测试和调整的迭代过程,只有结合具体业务场景,深入理解系统瓶颈,才能最大化 Node.js 的潜力,提供高效、稳定的服务体验
感谢支持



