走进前端二进制
在实际的开发过程中经常会遇到二进制数据,常见的就有文件的上传、下载等等,还有比较重要的图片裁剪、灰度处理等等,这些场景都会涉及到二进制。相信很多开发者对这方面可能一知半解或者就是久而忘之,本人刚开始也是对这方面空白,通过全方位的学习后其实也挺简单,整体总结可以直奔文中
前端二进制是一种关键的数据表示和处理技术,它在前端开发中具有广泛的应用。了解和掌握二进制数据有助于优化性能、原生数据的处理等等
ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区;它是一个字节数组,通常在其他语言中称为“byte array”。你不能直接操作 ArrayBuffer 中的内容;而是要通过 类型化数组对象 或 DataView 对象来操作
构造函数:
new ArrayBuffer(bytelength: number); // 创建指定字节的buffer缓冲区实例属性方法:
- byteLength:获取buffer的字节长度和构造函数传入的值相等
- slice:拷贝指定位置的内容并返回新的buffer
视图对象
arraybuffer只是创建了一块连续的内存地址引用,里面是什么内容不能直接读取,如果要操作buffer对象需要使用视图对象,这些视图对象只是用来解析buffer中的内容实际并不会储存任何内容
TypeArray
这些视图对象看上去更像数组Array,但他们并不是数组而是在ArrayBuffer上统称的类型术语,JS提供了多种视图对象:Uint8Array、Int8Array、Uint16Array、Int16Array、Uint32Array、Int32Array、Float32Array、Float64Array、Uint8ClampedArray、BigInt64Array、BigUint64Array等等
这些视图对象享有共有的方法和属性,所以搞懂某一个通用方法就可以了, 唯一不同的是不同的视图对象对buffer的解析不同如:Uint8Array中是以1字节8位为一个基本单位,Uint16Array则是以2字节16位为一个基本单位,如果buffer的长度为2字节,那么在uint8长度也为2,而uint16的长度则为1
Uint8Array
Uint8Array 数组类型表示一个 8 位无符号整型数组,8位为一个字节用来表示每个位置上的数字,也就是说Uint8的每一位的数字范围为:0 - 2^8-1(255),只需要记住每位是由1字节8位组成就可以推到出来(后面会有其他类型的数组都是同一个道理)
构造函数
类型定义:
new Uint8Array(); // 创建空长度
new Uint8Array(len: number); // 创建用0太填满的指定长度
new Uint8Array(array | arraylike); // 创建时指定值
new Uint8Array(buffer, byteOffset?, len?); // 从存在的buffer中的指定位置截取指定长度列子:
// 传入存在的buffer
const buffer = new ArrayBuffer(10);
new Uint8Array(buffer);
// 确定值
new Uint8Array([1,2,3])
// 创建指定长度
new Uint8Array(10); // 长度为10实例化Uint8Array底层都会创建相应的ArrayBuffer,对实例的操作都是作用到ArrayBuffer上
属性
- BYTES_PER_ELEMENT:每个元素的字节数,uint8为1字节8位,uint16为2字节16位,以此类推
- buffer:所引用的ArrayBuffer
- byteLength:所引用的ArrayBuffer的长度
- byteOffset:返回具体其引用ArrayBuffer的起始位置偏移量
- length:数组的长度
方法
Uint8Array等拥有数组Array的所有方法, 初次之外还有set方法常用来合并多个类型数组
一个将很大的图片分段请求最后合并下载的例子:
const buffers: ArrayBuffer[] = []; // 储存请求的所有的图片buffer
const bufferTotalLen = buffers.reduce((p, c) => (p += c.byteLength), 0); // buffer总长度
const allBuffer = new Uint8Array(bufferTotalLen); // 合并成最后的buffer
let position = 0, begin = 0;
while (begin < buffers.length) {
const subBuffer = new Uint8Array(buffers[begin]);
allBuffer.set(subBuffer, position);
position += subBuffer.length;
begin++;
}
const blob = new Blob([allBuffer.buffer], { type: "image/png" }); // 构造blob对象
const url = URL.createObjectURL(blob);
// ...除此之外的其他有关的ArrayBuffer的视图api雷同,可自行查看文档
以下是几个不同类型的array对同一段buffer的处理不同点: 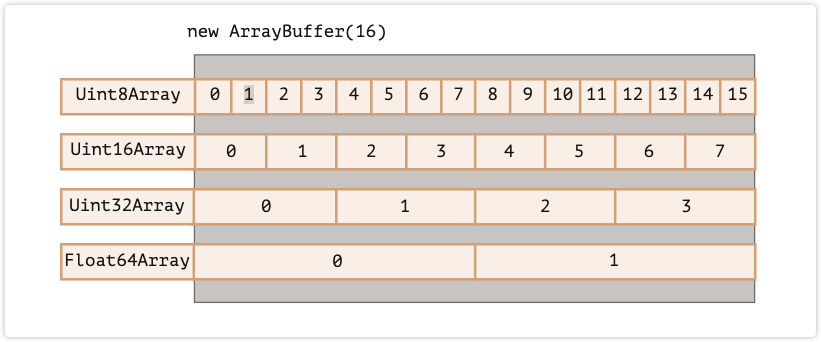
Uint8Array—— 将ArrayBuffer中的每个字节视为 0 到 255 之间的单个数字(每个字节是 8 位,因此只能容纳那么多)。这称为 “8 位无符号整数”。Uint16Array—— 将每 2 个字节视为一个 0 到 65535 之间的整数。这称为 “16 位无符号整数”。Uint32Array—— 将每 4 个字节视为一个 0 到 4294967295 之间的整数。这称为 “32 位无符号整数”。Float64Array—— 将每 8 个字节视为一个5.0x10-324到1.8x10308之间的浮点数。
DataView
DataView 是在 ArrayBuffer 上的一种特殊的超灵活“未类型化”视图。它允许以任何格式访问任何偏移量(offset)的数据
上面列出的TypeArray由于固定了格式所以每个索引的格式都是相同的,所以只能使用索引方式获取;而DataView没有固定格式直接作用于ArrayBuffer上,可以使用任何类型进行读取,所以更加灵活
构造方法
其构造方法需要传入buffer实例
new DataView(buffer, offset?, len?)属性
- byteLength:字节长度
- byteOffset:首位在ArrayBuffer中的偏移量
- buffer:ArrayBuffer引用对象
方法
- getUint8:以Uint8格式获取指定索引的数据
- setUint8:setUint8(idx, value)以Uint8格式设置某个索引位置的值,这些值需满足uint8的值范围。如
setUint8(0, 256)将不会满足0~255的范围限制,其值将会变为0
除了Uint8格式外还有其它TypeArray的格式相同方法,请参考MDN
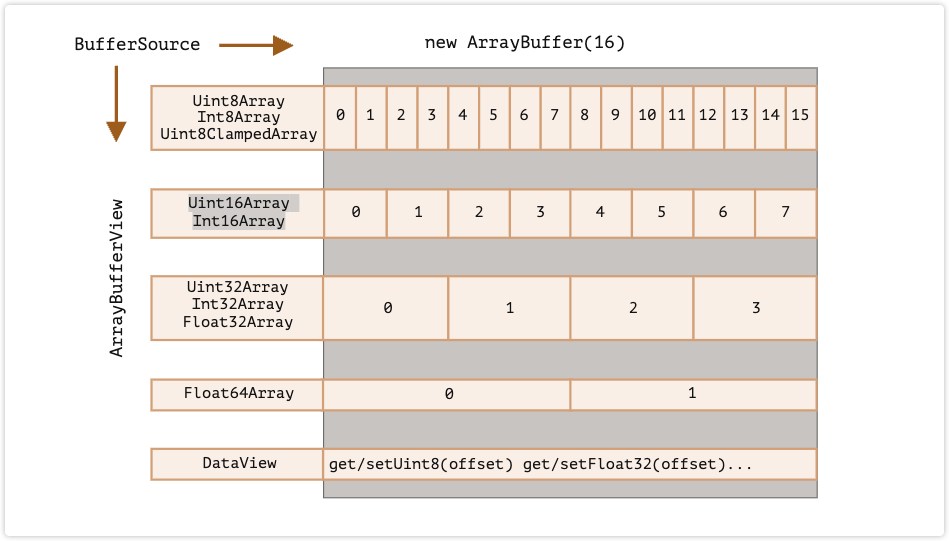
视图对象总结
字符二进制
除了一些二进制数据外,还可以将一些字符进行二进制的相互转换,js中提供了TextEncoder和TextDecoder分别将字符转为二进制、将二进制转为字符
TextEncoder例子:
// 将字符转换成Uint8Array
const encoder = new TextEncoder();
const uint8 = encoder.encode("测试");
console.log(uint8); // Uint8Array(6) [230, 181, 139, 232, 175, 149, buffer: ArrayBuffer(6), byteLength: 6, byteOffset: 0, length: 6]TextDecoder例子:
// 将ArrayBuffer转换成字符
const decoder = new TextDecoder("utf8");
console.log(decoder.decode(uint8)); // 测试
console.log(decoder.decode(uint8.buffer)); // 测试
console.log(decoder.decode(uint8.slice(0, 3))); // 测
console.log(decoder.decode(uint8.buffer.slice(0, 3))); // 测因为TypeArray位Uint8Array所以和ArrayBuffer的字节长度一致,所以对buffer或array的截取一致获取的结果也一样。从上面可以看到Uint8Array中的[230, 181, 139]表示一个字符测
const uint8 = new Uint8Array([230, 181, 139]);
const decoder = new TextDecoder("utf8");
decoder.decode(uint8); // 测字符二进制流
字符二进制通常用来处理比较大的数据字符流,而TextEncoder这种通常是一次性进行转换;二进制流也包含TextEncoderStream和TextDecoderStream两种方法
Blob
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream 来用于数据操作
前面我们讲了ArrayBuffer和TypeArray等相关二进制的方法, 但这些都是操作比较低级的数据,而blob则是有类型的二进制数据,相对于比较低级的数据更容易大家所理解
构造器
new Blob(blobParts, options);- blobParts:由blob、buffersource、string类型组成的数组值
- options:
- type:表示blob类型,通常都是mime类型
- endings:是否转换换行符,使 Blob 对应于当前操作系统的换行符(
\r\n或\n)。默认为"transparent"(啥也不做),不过也可以是"native"(转换)
例子:
// 将字符转为blob,并指定类型为 text/plain文本类型
new Blob(['测试'], { type: 'text/plain' });
// 将buffersource转为blob
new Blob([new Uint8Array([1,2,3])]);属性
- size:blob的数据大小
- type:blob的类型
方法
arrayBuffer:异步返回blob的二进制格式的ArrayBuffer
tsblob = new Blob(['一段文本'], { type: 'text/plain' }); buffer = await blob.arrayBuffer(); // ArrayBufferslice:划分指定范围的blob,类似于array的slice
stream:返回blob的可读流ReadableStream,通常流用来处理比较大的内容
tsconst readableStream = blob.stream(); const reader = readableStream.getReader(); while(true) { const { done, value } = await reader.read(); if (done) break; }text:异步返回blob的所有内容的UTF8格式的字符串
tsblob = new Blob(['一段文本'], { type: 'text/plain' }); text = await blob.text(); // 一段文本
除了使用自身的方法外, 还可以使用FileReader读取内容并转换
reader = new FileReader();
reader.onload = e => console.log(e.target.result);
reader.readAsText(blob);用途
用blob对象构造url使用,使用URL的createObjectURL方法生成一个唯一映射此blob的url
ts// 一个图片blob blob = new Blob([], { type: 'image/png' }); url = URL.createObjectURL(blob); img.src = url; // 使用后销毁 URL.revokeObjectURL();文件分片上传
tsconst blob = new Blob([]); const chunkSize = 1024 * 1024; blobs = []; offset = 0; while(offset < blob.size) { blobs.push(blob.slice(offset, chunkSize)); offset += chunkSize; } blobs.map(blob => fetch('xx', data: blob))
除了以上外对于canvas也可以转换为blob
const img = new Image();
const canvas = document.querySelector("canvas");
const ctx = canvas?.getContext("2d");
ctx?.drawImage(img, 0, 0);
canvas?.toBlob(e => console.log(e)); // 转为为 blob
canvas?.toDataURL("text/plain"); // 转为为 base64字符串File
文件(File)接口提供有关文件的信息,File 对象继承了 Blob,并扩展了与文件系统相关的功能,且可以用在任意的 Blob 类型的 context 中。比如说, FileReader, URL.createObjectURL, createImageBitmap, 及 XMLHttpRequest.send() 都能处理 Blob 和 File
File对象
通常有两种方式获取File对象:构造函数、<input type="file">
构造函数:
new File(bits: Array<ArrayBuffer | ArrayBufferView | String | Blob>, name, { type, lastModified })构造函数方式类似于blob的构造函数
例子:
const file = new File(['我是一段文本信息'], 'text.txt', { type: 'text/plain', lastModified: Date.now() })输入框获取:
// 用户点击选择文件后,可以通过属性获取
<input type="file">
console.log(e.files[0])属性
- lastModified:当前file的最后修改时间,毫秒数
- lastModifiedDate:最后修改时间date对象
- name:文件名字
- size:文件大小
- type:文件的mime类型
由于File继承于Blob对象所以也用了Blob的相关属性
方法
由于File继承于Blob对象所以也用了Blob的相关属性,如slice方法,通常用来对大文件做切片处理,参考以上blob的切片操作这里就不演示了
FileReader
FileReader 对象允许 Web 应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,主要目的就是从 File 或 Blob 对象中读取的文件或数据
构造函数
Filereader通过构造函数生成一个对象
const reader = new FileReader();属性
readyState:当前的读取状态,其中包含以下几个常量
常量名 值 描述 EMPTY0还没有加载任何数据。 LOADING1数据正在被加载。 DONE2已完成全部的读取请求。 result:读取完后的内容,读取操作后效,文件内容的格式取决于哪种读取方式
error:读取错误的对象
事件
- onabort:读取时中断时触发
- onerror:读取时发生错误时触发
- onload:所有内容的读取都是异步的,需要通过此事件获取读取的数据,读取成功后触发
方法
- abort:中断读取
- readAsArrayBuffer:将文件内容读取为arraybuffer形式的数据
- readAsDataURL:将文件内容读取为base64字符串
- readAsText:将文件内容读取为文本字符串
- readAsBinaryString:将文件内容读取为原始二进制数据
读取数据都是异步的,需要通过onload事件获取读取内容
FileReaderSync
FileReaderSync接口允许以同步的方式读取 File 或 Blob 对象中的内容,该接口只能在webwoker中使用,由于读取文件是非常耗时的过程,在主线程使用会造成页面卡顿现象,因此对于文件的操作在webwoker不会影响主线程
FileReaderSync和FileReader拥有相同的方法和属性,只不过前者的读取是同步的
// webwoker
function readFileSync(file) {
const reader = new FileReaderSync();
const buffer = reader.readAsArrayBuffer(file);
return buffer;
}Stream
Stream API 允许 JavaScript 以编程方式访问从网络接收的数据流,并且允许开发人员根据需要处理它们
流可以让程序不需要接受全部的内容后才可以展示操作,使用流可以将大型数据拆分成小块并逐步处理,如视频播放不需要加载全部减小延迟、提高内存的吞吐量
除此之外可以检测流何时开始或结束,将流链接在一起,根据需要处理错误和取消流,并对流的读取速度做出反应
流的基础应用围绕着使响应可以被流处理展开。例如,一个成功的 fetch 请求返回的响应体可以暴露为 ReadableStream,之后你可以使用 ReadableStream.getReader 创建一个 reader 读取它,使用 ReadableStream.cancel 取消它等等。
更复杂的应用包括使用 ReadableStream 构造函数创建你自己的流,例如进入 service worker 去处理流
ReadableStream
ReadableStream 可以构造一个可读流,在前端领域通常fetch的 Response的body属性 就是一个ReadableStream对象
构造函数
new ReadableStream(underlyingSource?, queuingStrategy?)underlyingSource包括以下属性:
- start(controller):对象在创建时会执行,controller是个 ReadableStreamDefaultController ,通常在自己构造可读流时在此方法中 使用 controller.equeue 方法往可读流中添加数据;可以返回promise,则下一次的必须等待上一次结束后才会执行
- pull(controller):流内部队列不满时会重复调用这个方法,根据流的背压来判断流有没有满,通常这里不做任何事
- cancel(reason):当流被取消时触发,如:取消、出错等等
- type:表示流的内容类型,通常都是bytes
queuingStrategy 定义流的队列策略 背压
- highWaterMark:在背压前内部队列可以容纳的总块数
- size:每个chunk的大小
例子:
const chunks = [...];
let offset = 0;
new ReadableStream(
{
start(controller) {
console.log("开始读取");
async function read() {
if (offset < chunks.length) {
const chunk = chunks[offset];
// 往可读流中写入数据
controller.enqueue(chunk);
read();
} else {
console.log('读取结束');
// 关闭
controller.close();
}
}
read();
},
type: "bytes",
},
{ highWaterMark: 100 } // 定义背压
);这个例子自定义了一个可读流,在构建ReadableStream时不断地往可读流中写入数据,以便可读流可以读取到数据
ReadableStream构造函数返回一个可读流实例,其包含多个方法和属性
实例属性
- locked:返回改可读流是否被锁定到一个reader,也就是说当被锁定时,同时只能被一个可读流使用
实例方法
cancel:取消流的读取,取消后会触发内部的cancel属性
getReader:创建一个读取器并将流锁定于其上,其他读取器将不能读取它直到它被释放;这个读取器是一个 ReadableStreamDefaultReader 实例,其包含 read、cancel等方法,通常都是使用 read来读取 ReadableStream 内部的数据
ts// 一个简单的例子 const readstream = new ReadableStream(); // 假如自定义的可读流内部有数据 const reader = readstream.getReader(); // 获取 reader对象 while(true) { const { done, value } = await reader.read(); // 不断读取数据 if (done) { console.log('读取完毕'); } else { console.log('当前数据块:', value); } }上面演示了下从自己创建的可读流中读取,通常都是从fetch的response的body属性中获取reader,然后不断读取接受的数据 (注:response的body属性是一个 ReadableStream)
pipeThrough:提供将当前流管道输出到一个转换(transform)流或可写/可读流对的链式方法。简单来说就是一个管道对原始数据做点什么,比如修改、压缩啥的,对于平时的需求一般用不上,不过使用此功能可以很方便的做到一些有趣的效果
pipeThrough类型定义为:
tspipeThrough(transformStream, options?)transformStream是由可读流和可写流组成的 TransformStream(或者结构为
{writable, readable}的对象),writable 流写入的数据在某些状态下可以被 readable 流读取。详细使用请看WriableStreampipeTo:将当前 ReadableStream 管道输出到给定的 WritableStream,此方法是个异步方法,当所有的写入操作结束后表示结束
pipeTo类型定义:
tspipeTo(destination, options?)destination表示一个可写流WriableStream对象
tee:拷贝当前可读流,返回包含两个 ReadableStream 实例分支的数组
WritableStream
WritableStream 接口将流数据写入目的地,该对象带有内置的背压和队列,一般是将可读流的数据写入
构造函数
new WritableStream(underlyingSink, queuingStrategy)underlyingSink包括以下属性:
start(controller):对象被构建时立刻执行,controller是一个 WritableStreamDefaultController 对象
write(chunk, controller):当一个新的数据准备好写入底层接收器时调用此方法,chunk表示当前要写入的数据块,controller同上。一般可以在这里对数据的进行进度条计算
close(controller):所有数据写入完毕后将会调用此方法
abort(reason):可写流取消或出现错误时触发
queuingStrategy 定义流的队列策略 背压
- highWaterMark:在背压前内部队列可以容纳的总块数
例子:
// 模拟请求
const res = await fetch();
const totalLength = xxx;
let offset = 0;
const uint8 = new Uint8Array(totalLength);
// 定义背压
const highWaterMark = new CountQueuingStrategy({ highWaterMark: 100 });
const writer = new WritableStream(
{
write(chunk: Uint8Array, controller) {
return new Promise(resolve => {
uint8.set(chunk, offset); // 将读取的数据储存
offset += chunk.byteLength; // 计算已经接受到的数据大小
progress.textContent =
((offset / totalLength) * 100).toFixed(2) + "%"; // 计算进度
setTimeout(resolve, 0);
});
},
},
highWaterMark // 设置背压,避免大文件读到内存中
);
await res.body?.pipeTo(writer); // 记住 fetch的Response的body是个可读流,使用pipeTo方法以上通过将fetch的Response的body可读流通过自定义的WriableStream写入,在write方法中对每块数据进行获取,并计算进度
WritableStream构造函数返回一个可写流实例,其包含多个方法和属性
实例属性
- locked:表示 WritableStream 是否锁定到一个 writer
实例方法
abort:取消流的写入,会触发内部的abort属性方法
close:关闭可写流,会触发内部的close属性方法
getWriter:获取返回一个新的 WritableStreamDefaultWriter 实例并且将流锁定到该实例,该实例对象包含abort、close、write方法;还包含一个ready属性返回一个promise,当流填充内部队列的所需大小从非正数变为正数时兑现,表明它不再应用背压
tsconst chunks: Uint8Array[] = []; const highWaterMark = new CountQueuingStrategy({ highWaterMark: 100 }); const writeStream = new WritableStream( { write(chunk) { return new Promise(resolve => { // chunk为读取的数据,用它做点啥... resolve(); }); }, }, highWaterMark ); const writer = writeStream.getWriter(); // 获取writer对象 chunks.forEach(chunk => writer.ready.then(() => writer.write(chunk))); // 循环读取数据
TransformStream
TransformStream 接口表示链式管道传输(pipe chain)转换流(transform stream)概念的具体实现。他可以用于将编码或解码视频帧、压缩或解压缩数据或以其他的方式从一种数据转换成另一种数据
以下是一个将小写字母变成大写字母例子:
const strs = ["a", "b", "c", "d"];
let offset = 0;
const reader = new ReadableStream({
start(controller) {
function read() {
if (offset < strs.length) {
controller.enqueue(strs[offset]);
offset++;
read();
} else {
controller.close();
}
}
read();
},
});
const transfer = new TransformStream({
transform(chunk: string, controller) {
console.log("transform:", chunk);
controller.enqueue(chunk.toUpperCase());
},
});
const writer = new WritableStream({
write(chunk) {
console.log("write:", chunk);
},
});
reader.pipeThrough(transfer).pipeTo(writer);Response.body
一个 ReadableStream,或者对于使用空的 body 属性构建的任意的 Response 对象,或没有任何主体的实际 HTTP 响应,则为null
实践
视频流
页面上添加视频播放器:
// 视频播放器
<video src="/api/video/range" controls="controls" muted style="max-width: 100%;"></video>node端进行返回请求数据,默认在没有结束范围时只返回1M的数据,如果有结束返回就返回指定范围的数据:
// 对视频进行范围请求
@Get('/api/video/range')
async getVideoRanges(@Req() req: Request, @Res() res: Response) {
// 直接打开链接时禁止访问
const referer = req.headers.referer;
const host = req.headers.host;
const url = referer && new URL(referer);
if (!referer || url?.host !== host) {
throw new ForbiddenException('禁止访问');
}
const requestRange = req.headers['range'];
const parts = requestRange?.replace(/bytes=/, '').split('-');
const filePath = resolve(__dirname, '../data/video.mp4');
const fileStat = await stat(filePath);
const fileSize = fileStat.size;
const start = Math.min(parseInt(parts?.[0], 10) || 0, fileSize - 1); // 这里的大小值需减1
const end = Math.min(
parseInt(parts?.[1]) || start + 1024 * 1024, // 每次没有结束值,只返回1MB的数据
fileSize - 1,
);
const chunkSize = end - start + 1;
const head = {
'Content-Range': `bytes ${start}-${end}/${fileSize}`,
'Accept-Ranges': 'bytes',
'Content-Length': chunkSize,
'Content-Type': 'video/mp4',
};
// range请求返回部分内容
if (requestRange) {
const stream = createReadStream(filePath, { start, end });
res.writeHead(206, head);
stream.pipe(res);
} else {
// 非range请求返回整个视频
res.writeHead(200, {
'Content-Length': fileSize,
'Content-Type': 'video/mp4',
});
createReadStream(filePath).pipe(res);
}
}效果演示: 
文件下载
生活中会遇到文件的下载这种场景,主要还是读取文件流写入到blob中,这样也可以获取到指定的进度。需要注意的是这种方式不适合大文件的下载,容易撑爆内存,具体的大文件下载可以查看我的「如何实现大文件下载」 一文
// 请求资源
async function fetchBigImage() {
progress.setAttribute('style', 'transform: translate3d(-100%, 0, 0)');
progressNum.textContent = 0.00;
const res = await fetch('/big-size.png');
const fileSize = res.headers.get('content-length');
const filename = res.headers.get('Content-Disposition')?.split(";")[1]?.split('=')[1] || res.url.match(/\/([^\/]\.[^\/]*)/i)?.[1] || 'download.txt';
const blobs = [];
let downloaded = 0;
const writer = new WritableStream({
write(chunk) {
blobs.push(chunk);
downloaded += chunk.length;
const percentComplete = (downloaded / fileSize) * 100;
progress.setAttribute('style', `transform: translate3d(-${(100 - percentComplete).toFixed(2)}%, 0, 0)`);
progressNum.textContent = percentComplete.toFixed(2);
},
close() {
useDownload(filename, ...blobs);
}
});
res.body.pipeTo(writer);
}
// 下载
function useDownload(filename, ...blobs) {
const blob = new Blob([...blobs]);
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.setAttribute('href', url);
a.download = filename || 'file.txt';
a.click();
a.remove();
URL.revokeObjectURL(url);
}大文件上传
请阅读我的 「如何实现大文件上传」 一文
感谢支持



